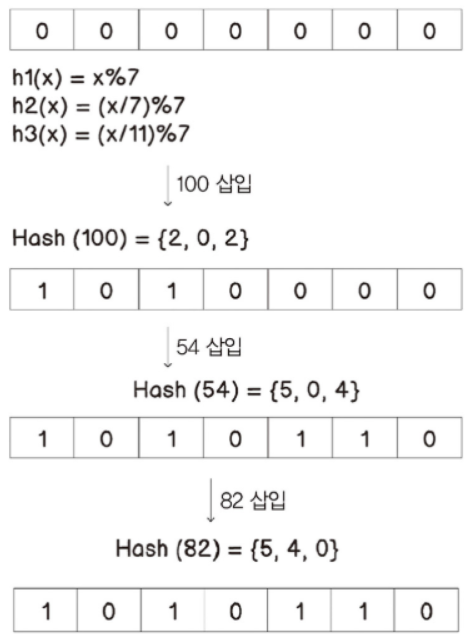
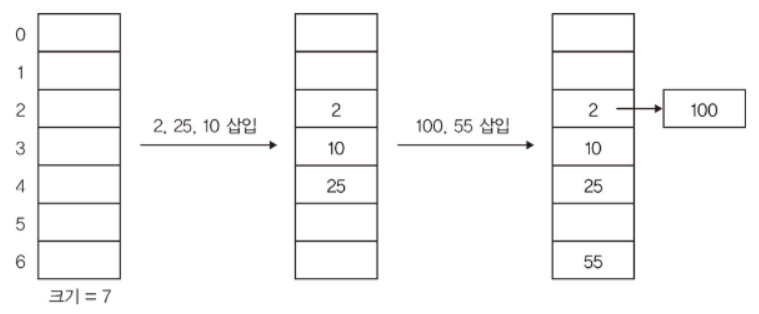
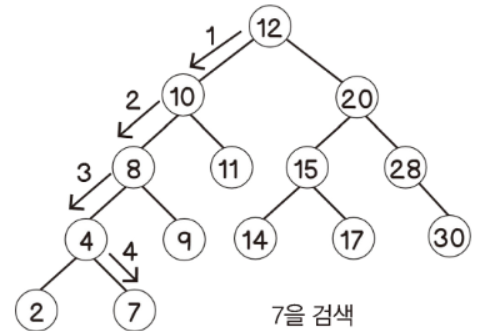
블룸 필터(bloom filter)블룸 필터는 해시 테이블에 비해 공간 효율이 매우 높은 방법이지만, 결정적(deterministic) 솔루션 대신 부정확한 결과를 얻을 수 있다.거짓-부정(false-negative)dl 이 없다는 것은 보장하지만, 거짓-긍정(false-positive)는 나올 수 있다.즉, 특정 원소가 존재한다는 긍정적인 답변을 받을 경우, 이 원소는 실제로 있을 수도 있고 없을 수도 있다.그러나 특정 원소가 존재하지 않는다는 부정적인 답변을 받았다면 이 원소는 확실히 없다뻐꾸기 해싱과 마찬가지로 블룸 필터도 여러 개의 해시 함수를 사용한다정확도를 위해 세 개 이상을 사용해야 한다블룸 필터는 실제 값을 저장하지는 않으며, 대신 특정 값이 있는지 없는지를 나타내는 부울 타입 배열을 사용..