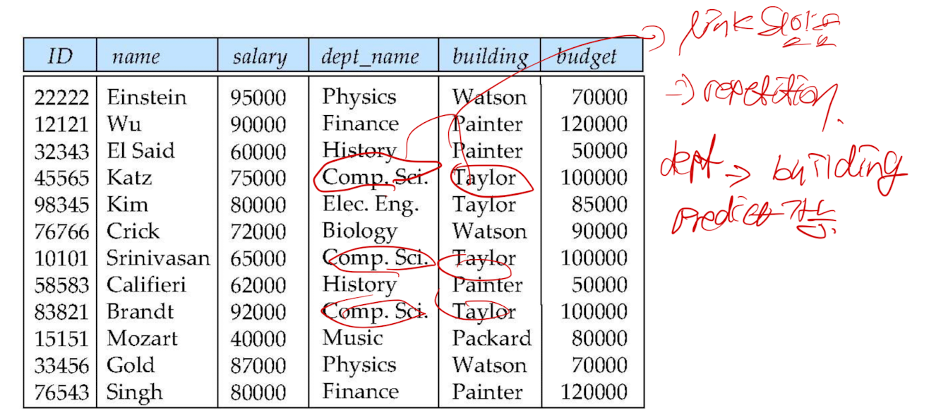
Normalization(빅데이터 등장 이후 잘 안쓰긴 합니다. 그래도 RDB에서는 중요해요)좋은 relational design 생성instructor와 department를 in_dept으로 결합한다고 가정, 이는 instructor와 department 간의 natural join을 나타냄정보의 반복이 있음Null 값을 사용해야 함 (새로운 부서를 추가하는 경우, instructor가 없는 경우)Decompositionin_dep schema에서 정보 반복 문제를 피하는 유일한 방법은 이를 두 개의 schema - instructor와 department schema -로 분해하는 것임모든 Decomposition가 좋은 것은 아님. 예를 들어, employee(ID, name, street, ci..