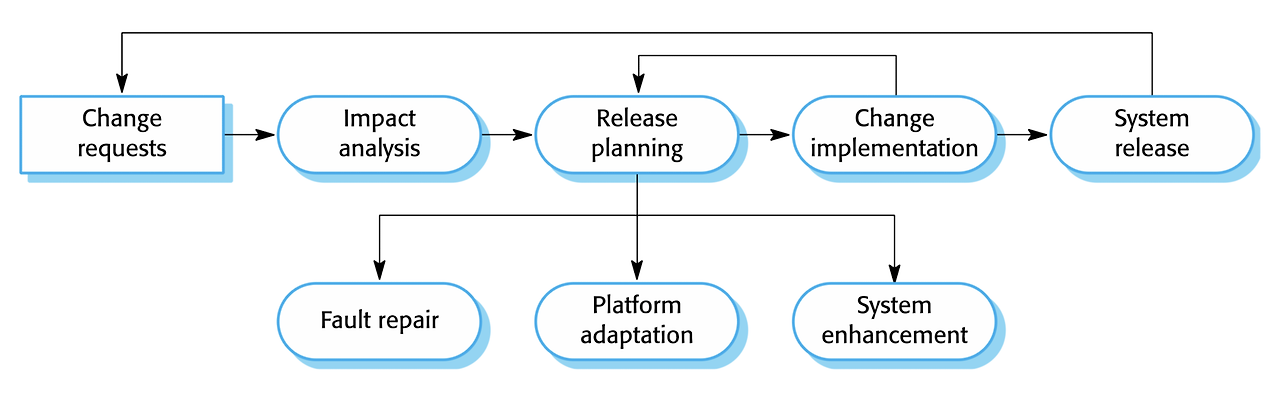
Software Reuse를 왜 하나요?더 나은 SW를 빠르고 저렴하게 달성하기 위해서 하는 것.System부터 Application, component, Object and function 까지 모두 가능 Benefits of software reuse (외워야 하나..?)BenefitExplanationAccelerated development시스템을 가능한 한 빨리 시장에 출시하는 것이 전체 개발 비용보다 중요한 경우가 많습니다. 소프트웨어 재사용은 개발 및 검증 시간의 단축(both development and validation time may be reduced)으로 시스템 생산을 가속화할 수 있습니다.Effective use of specialists동일한 작업을 반복해서 수행하는 대신, 응..