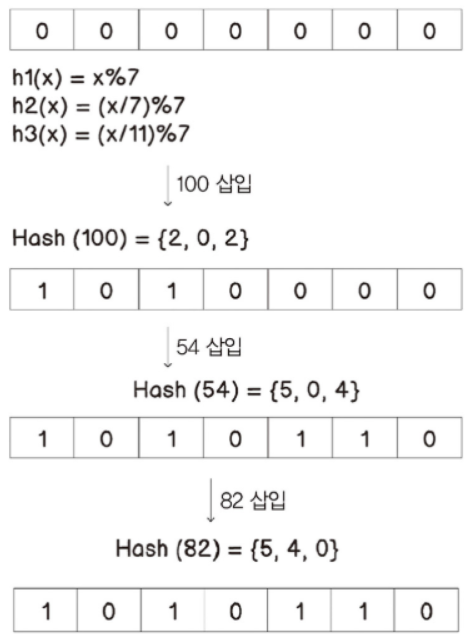
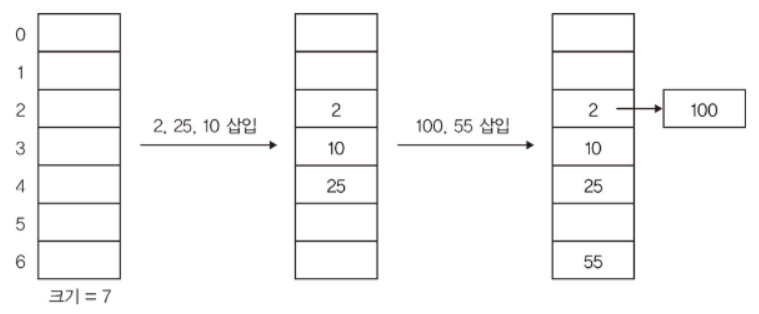
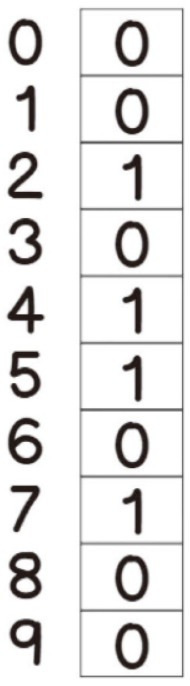
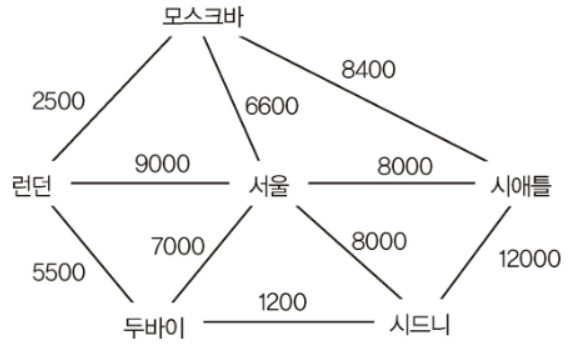
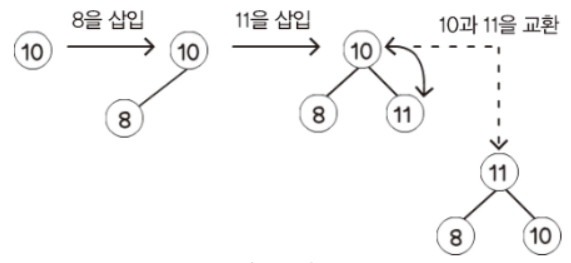
컬렉션#Abstract/Java/Collection 인터페이스/List 자료 구조/ArrayList - 배열 리스트/연결리스트 - LinkedList/자바 List 인터페이스/자바 ArrayList/자바 LinkedList/Set/해시 알고리즘/자바의 hashCode()/자바 Set 인터페이스/Map 인터페이스/Stack - 사용 금지/Queue 인터페이스/Deque 인터페이스/Deque와 Stack, Queue/순회/Iterable, Iterator/자바가 제공하는 Iterable, Iterator/정렬 - Comparable, Comparator/컬렉션 유틸/Collection 인터페이스 정리Collection 인터페이스Collection 인터페이스는 java.util 패키지의 컬렉션 프레임워크의 핵..