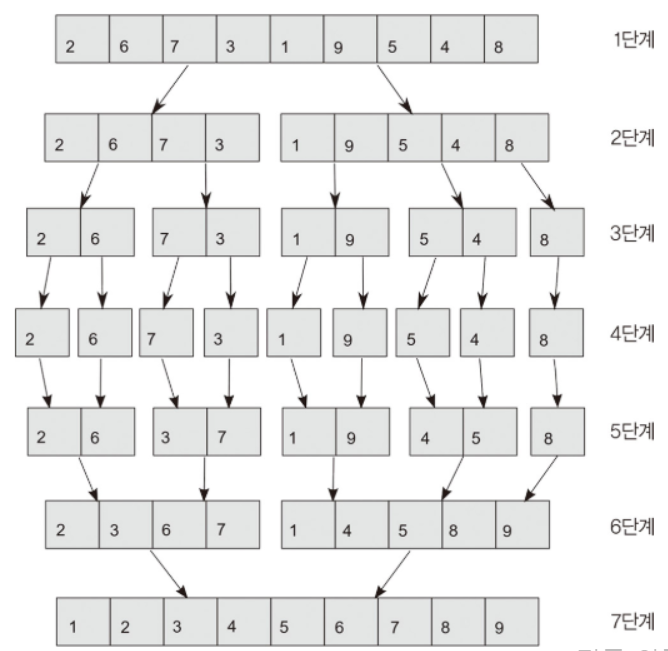
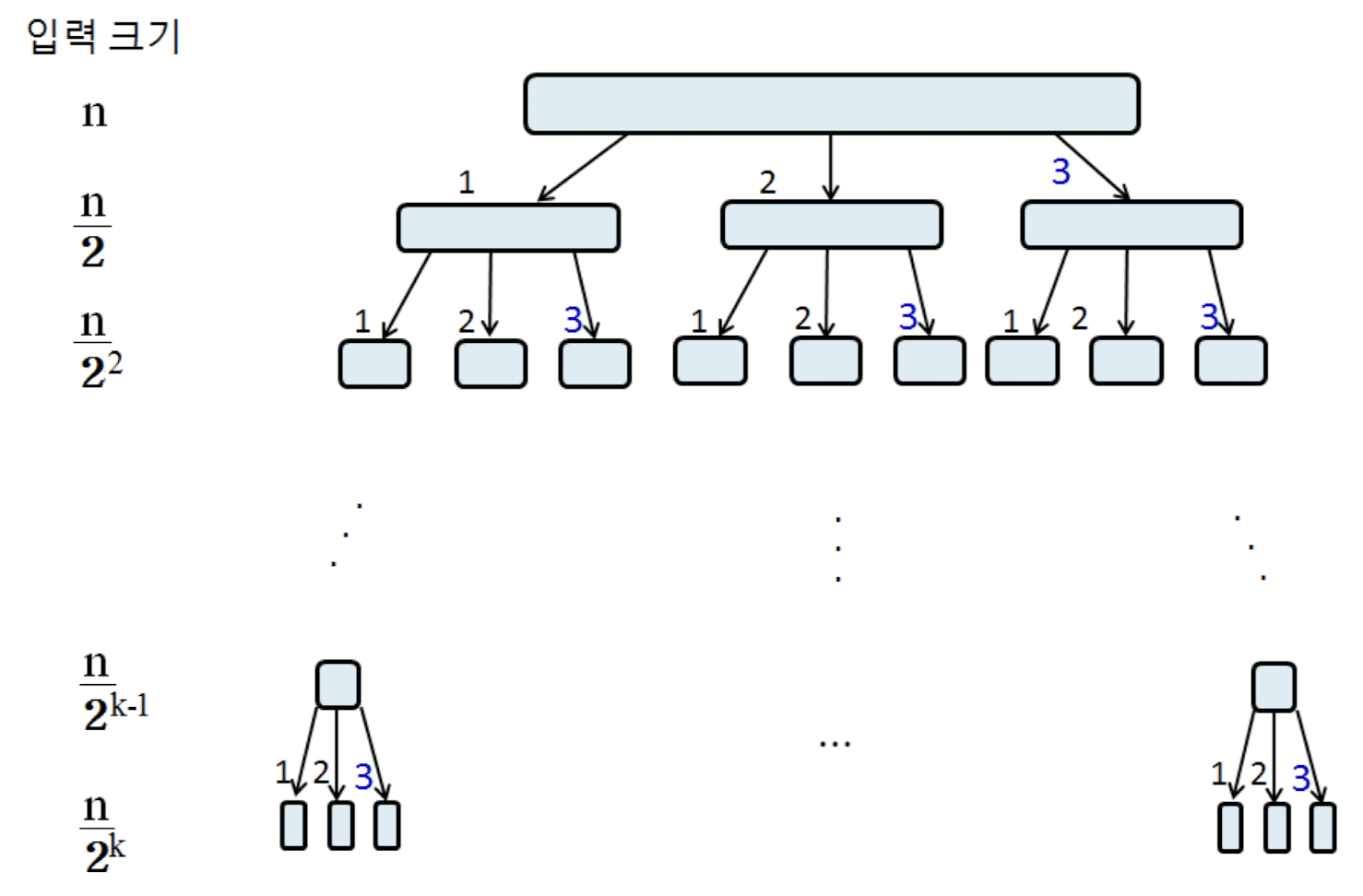
선택 문제n개의 숫자들 중에서 k 번째로 작은 숫자를 찾는 문제이다.선택 문제 해결 방법간단한 방법 1. 최소 숫자를 k번 찾는다. 단 최소 숫자를 찾은 뒤에는 입력에서 최소 숫자를 제거한다숫자를 제거하는 과정에서 추가 수행시간 또는 추가 메모리가 필요하다O(kn)간단한 방법 2 : 숫자들을 정렬한 후 k 번째 숫자를 찾는다.O(nlogn)의 수행 시간이 필요하다k가 작을 경우 최소 숫자를 k번 찾는 것이 유리하고, 그렇지 않은 경우 정렬하여 찾는 것이 유리하다이진탐색 아이디어를 활용해보자이진 탐색에서는 정렬된 입력의 중간에 있는 숫자와 찾고자 하는 숫자를 비교함으로써 입력을 1/2로 나눈 두 부분 중에서 한 부분만 검색했다.분할 후 각 그룹의 크기를 알아야 k번째 작은 숫자가 어느 그룹에 있는지를 알..