퀵 정렬이란?
- 이전 챕터에서 본 병합 정렬의 목적이 대용량의 데이터를 정렬하는 것이라면, 퀵 정렬은 평균 실행 시간을 줄이는 것이 목표이다.
- 분할 정복 접근법을 이용하는 기본 아이디어는 병합 정렬과 동일하다.
- 다만 퀵 정렬의 핵심은 병합이 아니라 분할이다.
- 퀵 정렬은 문제를 2개의 부분문제로 분할하는데, 각 부분문제의 크기가 일정하지 않은 형태의 비균등 분할 정복 알고리즘이다
퀵 정렬의 분할 연산 방법
입력 배열이 주어지고, 입력 배열 중 피벗(pivot) 원소 P를 선택했을 경우, 퀵 정렬을 위한 분할 연산은 다음 두 단계로 이루어진다
- 입력 배열을 두 개의 부분 배열 L과 R로 나눈다. L은 입력 배열에서 P보다 작거나 같은 원소를 포함하는 부분 배열이고, R은 입력 배열에서 P보다 큰 원소를 포함하는 부분 배열이다.
- 입력 배열을 L, P, R 순서로 재구성한다
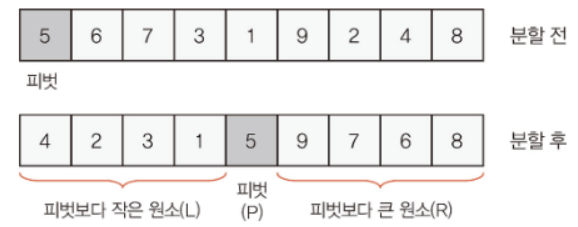
이러한 방식으로 분할 연산을 수행하면 피벗 P는 배열이 최종적으로 정렬되었을 때 P가 실제로 있어야 하는 위치로 이동하게 된다.
즉, 배열 전체를 오름차순으로 정렬했을 경우, 해당 Pivot의 수가 있어야 하는 위치로 이동한 것이다.
이러한 특징이 퀵 정렬 알고리즘의 핵심 아이디어이다. 전체 퀵 정렬 알고리즘은 다음과 같다.
- 입력 배열 A가 두 개 이상의 원소를 가지고 있다면 A에 분할 연산을 수행한다 (L과 R 배열 생성)
- 1단계의 입력으로 L을 사용한다
- 2단계의 입력으로 R을 사용한다
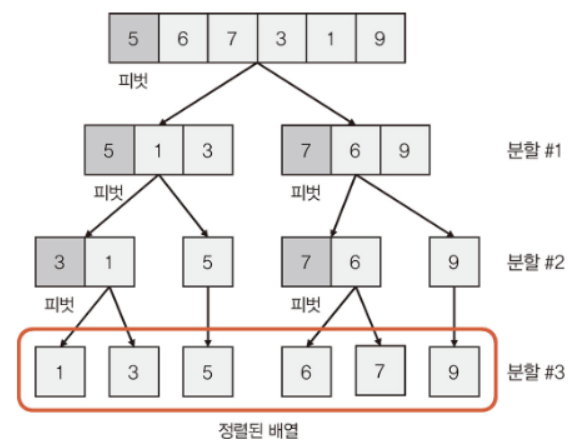
여기서 2, 3단계는 분할 연산에 의해 생성된 부분 배열에 재귀적으로 적용된다. 분할 연산을 재귀적으로 반복하면 모든 원소가 차츰 오름차순으로 정렬된다.
아래 예제처럼 입력 배열이 어떤 순서로 되어 있는지 알 수 없는 경우 임의의 원소를 피벗으로 선택하여 사용해도 무방하다
퀵 정렬 구현(C++)
다음은 분할 동작을 위한 partition 함수의 구현이다
template <typename T>
auto partition(typename std::vector<T>::iterator begin, typename std::vector<T>:: iterator end) {
// 세 개의 반복자를 생성한다
// 하나는 피벗을 가리키고, 나머지 둘은 벡터의 시작과 마지막 원소를 가리킨다
// 여기서는 첫 번째 원소를 피벗으로 사용한다
auto pivot_val = *begin;
auto left_iter = begin + 1;
auto right_iter = end;
while (true) {
// 벡터의 첫 번째 원소부터 시작하여 피벗보다 큰 원소를 찾는다
while (*left_iter <= pivot_val && std::distance(left_iter, right_iter) > 0)
left_iter++;
// 벡터의 마지막 원소부터 시작하여 역순으로 피벗보다 작은 원소를 찾는다
while (*right_iter > pivot_val && std::distance(left_iter, right_iter) > 0)
right_iter--;
// left_iter == right_iter이면 교환할 원소가 없음을 의미
// 그렇지 않으면 left_iter와 right_iter가 가리키는 원소를 서로 교환한다
if (left_iter == right_iter)
break;
else
std::iter_swap(left_iter, right_iter);
}
if (pivot_val > *right_iter) {
std::iter_swap(begin, right_iter);
}
return right_iter;
}
- partition() 함수는 컨테이너 객체에서 분할 연산을 적용할 원소의 시작과 끝 반복자를 인자로 받고, 분할 연산에 의해 생성되는 오른쪽 부분 배열의 시작 원소를 가리키는 반복자를 반환한다.
- 즉, 주어진 벡터가 분할되어 피벗보다 큰 원소는 오른쪽 부분에 위치하게 되고, 피벗보다 작거나 같은 원소는 왼쪽 부분에 나타나게 된다
다음은 분할 연산을 재귀적으로 호출해 퀵 정렬을 수행하는 quick_sort() 함수이다
template<typename T>
void quick_sort(typename std::vector<T>::iterator begin, typename std::vector<T>::iterator last) {
// 만약 벡터에 하나 이상의 원소가 있다면
if (std::distance(begin, last) >= 1) {
// 분할 작업을 수행
auto partition_iter = partition<T>(begin, last);
// 분할 작업에 의해 생성된 벡터를 재귀적으로 정렬
quick_sort<T>(begin, partition_iter - 1);
quick_sort<T>(partition_iter, last);
}
}
전체 프로그램
#include <iostream>
#include <vector>
template <typename T>
auto partition(typename std::vector<T>::iterator begin, typename std::vector<T>::iterator end)
{
// 세 개의 반복자 생성
// 하나는 피벗을 가리키고, 나머지 둘은 벡터의 시작과 마지막 원소를 가리킴
auto pivot_val = *begin;
auto left_iter = begin + 1;
auto right_iter = end;
while(true)
{
// 벡터의 첫 번째 원소부터 시작하여 피벗보다 큰 원소를 찾음
while(*left_iter <= pivot_val && std::distance(left_iter, right_iter) > 0)
left_iter++;
// 벡터의 마지막 원소부터 시작하여 역순으로 피벗보다 작은 원소를 찾음
while(*right_iter > pivot_val && std::distance(left_iter, right_iter) > 0)
right_iter--;
// 만약 left_iter와 right_iter가 같다면 교환할 원소가 없음을 의미
// 그렇지 않으면 left_iter와 right_iter가 가리키는 원소를 서로 교환
if(left_iter == right_iter)
break;
else
std::iter_swap(left_iter, right_iter);
}
if(pivot_val > *right_iter)
std::iter_swap(begin, right_iter);
return right_iter;
}
template <typename T>
void quick_sort(typename std::vector<T>::iterator begin, typename std::vector<T>::iterator last)
{
// 만약 벡터에 하나 이상의 원소가 있다면
if(std::distance(begin, last) >= 1)
{
// 분할 작업 수행
auto partition_iter = partition<T>(begin, last);
// 분할 작업에 의해 생성된 벡터를 재귀적으로 정렬
quick_sort<T>(begin, partition_iter - 1);
quick_sort<T>(partition_iter, last);
}
}
template <typename T>
void print_vector(std::vector<T> arr)
{
for(auto i : arr)
std::cout << i << " ";
std::cout << std::endl;
}
void run_quick_sort_test()
{
std::vector<int> S1 { 45, 1, 3, 1, 2, 3, 45, 5, 1, 2, 44, 5, 7 };
std::vector<float> S2 { 45.6f, 1.0f, 3.8f, 1.01f, 2.2f, 3.9f, 45.3f, 5.5f, 1.0f, 2.0f, 44.0f, 5.0f, 7.0f };
std::vector<double> S3 { 45.6, 1.0, 3.8, 1.01, 2.2, 3.9, 45.3, 5.5, 1.0, 2.0, 44.0, 5.0, 7.0 };
std::vector<char> C { 'b', 'z', 'a', 'e', 'f', 't', 'q', 'u', 'y' };
std::cout << "정렬되지 않은 입력 벡터" << std::endl;
print_vector<int>(S1);
print_vector<float>(S2);
print_vector<double>(S3);
print_vector<char>(C);
std::cout << std::endl;
// arr.end()는 맨 마지막 원소 다음을 가리키므로 -1 형태로 호출
quick_sort<int>(S1.begin(),S1.end() - 1);
quick_sort<float>(S2.begin(),S2.end() - 1);
quick_sort<double>(S3.begin(),S3.end() - 1);
quick_sort<char>(C.begin(),C.end() - 1);
std::cout << "퀵 정렬 수행 후의 벡터" << std::endl;
print_vector<int>(S1);
print_vector<float>(S2);
print_vector<double>(S3);
print_vector<char>(C);
std::cout << std::endl;
}
int main()
{
run_quick_sort_test();
return 0;
}퀵 정렬의 시간 복잡도
- 퀵 정렬의 성능은 피봇 선택이 좌우한다.
- 피봇으로 가장 작은 숫자 또는 가장 큰 숫자가 선택되면, 한 부분으로 치우치는 분할을 야기한다.
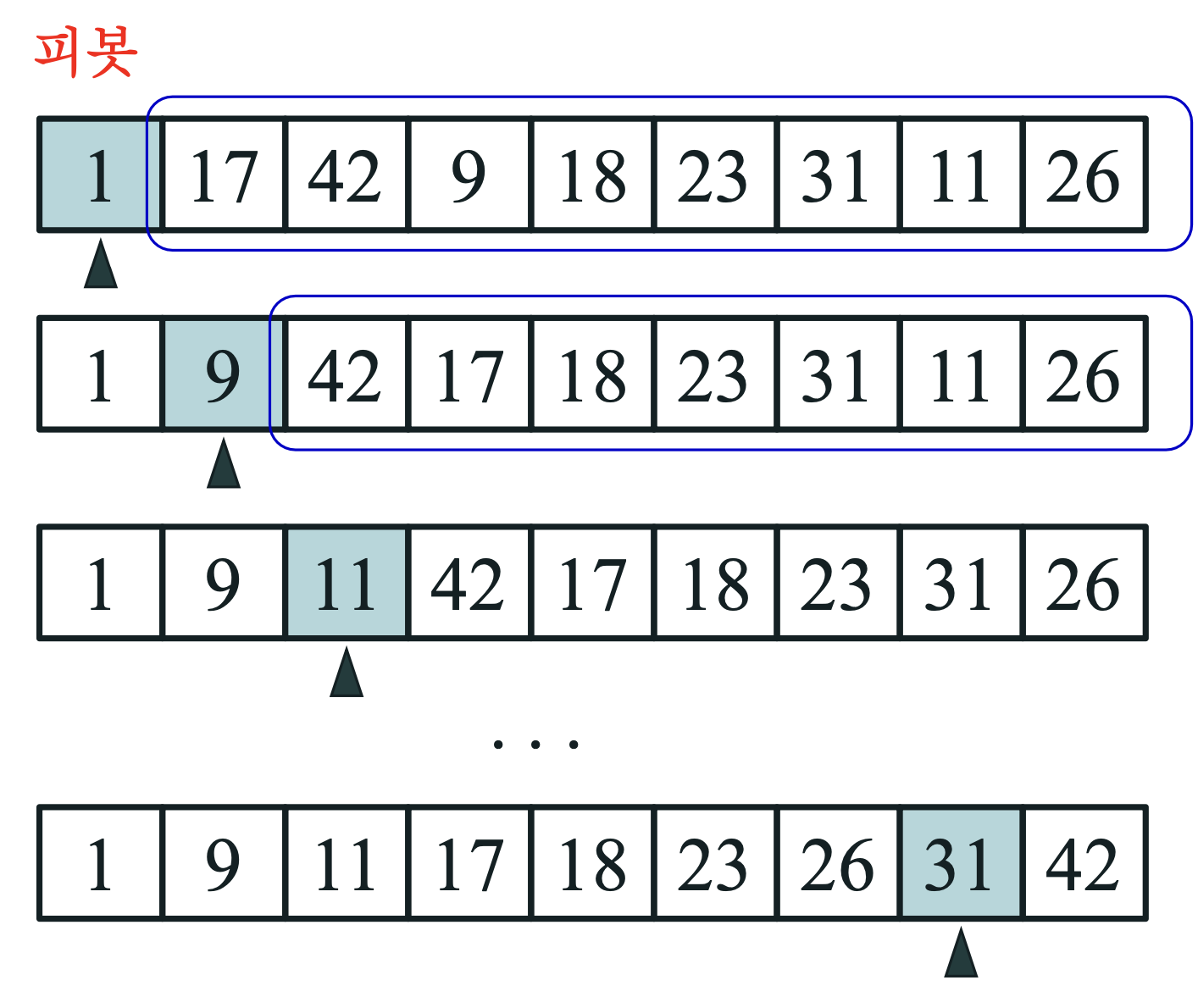
- 최악의 경우 시간복잡도를 생각해보자(입력의 크기가 n인 경우)
- (n-1) + (n-2) + (n-3) + ... + 2 + 1 = n(n-1) / 2 = O(n^2)
- 최선의 경우 시간 복잡도를 생각해보자
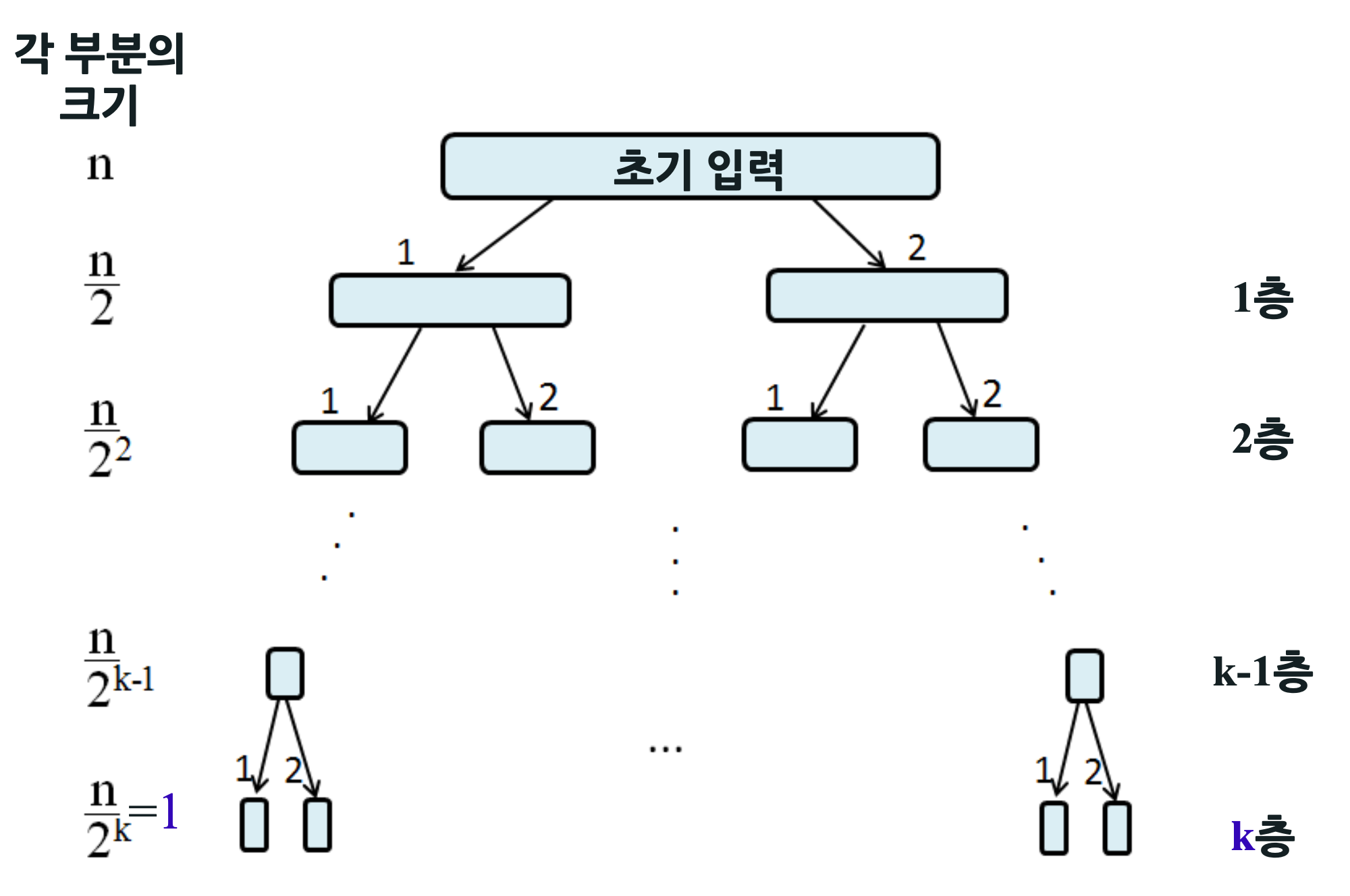
- 각 층에서 각가의 원소가 각 부분의 피봇과 1회씩 비교된다
- 따라서 비교 횟수 = n
- 총 비교 횟수: n X (층수) = nlog_2 (n)
- 따라서 퀵 정렬의 최선 경우 시간복잡도 : O(nlog_2 (n))
- 피봇을 항상 랜덤하게 선택한다고 가정하면, 최선 경우와 동일하다
피봇 선정 방법
- 랜덤 선정 방법
- 가장 왼쪽, 중간, 오른쪽 숫자 중에서 중간 값으로 피봇을 정한다
성능 향상 방법
- 입력 크기가 매우 클 때, 퀵 정렬의 성능을 더 향상시키기 위해 삽입 정렬이 동시에 사용
- 분할하다가 입력의 크기가 작아질 때는 퀵 정렬이 삽입 정렬보다 빠르지만은 않다. 퀵정렬은 재귀 호출로 수행되기 때문이다
응용
- 퀵 정렬은 커다란 크기의 입력에 대해서 가장 좋은 성능을 보이는 정렬 알고리즘이다.
- 퀵 정렬은 실질적으로 어느 정렬 알고리즘보다 좋은 성능을 보인다
- C++ 표준 라이브러리의 std::sort()함수에서 사용된다
Ref) 코딩 테스트를 위한 자료 구조와 알고리즘 with C++
Ref) 알기쉬운 알고리즘
'Computer Science > Algorithm' 카테고리의 다른 글
| [Algorithm/Divide&Conquer] 06. 분할 정복 기법과 C++ 표준 라이브러리 함수 (0) | 2024.07.02 |
|---|---|
| [Algorithm/Divide&Conquer] 05. 선택(selection) 문제, 선형 시간 선택 (0) | 2024.07.01 |
| [Algorithm/Divide&Conquer] 03. Merge Sort(병합 정렬) (0) | 2024.07.01 |
| [Algorithm/Divide&Conquer] 02. 이진 검색(binary search) (0) | 2024.07.01 |
| [Algorithm/Divide&Conquer] 01. 분할 정복(Divide & Conquer) 알고리즘 (0) | 2024.07.01 |