이 부분은 직접 테이블을 만들고 SQL 언어를 사용해보면서 익히는 것이 중요해요!
SQL Parts
- DDL (데이터 정의 언어, Data Definition Language)
- DML (데이터 조작 언어, Data Manipulation Language)
- DCL (데이터 제어 언어, Data Control Language)
- TCL (트랜잭션 제어 언어, Transaction Control Language)

SQL Parts
- DDL
- Data definition language (DDL)은 데이터 구조, 특히 데이터베이스 스키마를 정의하기 위한 컴퓨터 프로그래밍 언어와 유사한 구문입니다.
- DDL 문은 데이터베이스 객체(테이블, 인덱스, 사용자 등)를 생성, 수정, 제거합니다.
- 일반적인 DDL 문은 CREATE, ALTER, DROP입니다.
- DML
- DML은 데이터베이스에서 정보를 쿼리하고 튜플을 삽입, 삭제, 수정할 수 있는 기능을 제공합니다.
SQL Parts
- 무결성 (Integrity)
- DDL은 integrity constraints(무결성 제약 조건)을 지정하기 위한 명령을 포함합니다.
- 뷰 정의 (View Definition)
- DDL은 View를 정의하기 위한 명령을 포함합니다.
- 트랜잭션 제어 (Transaction Control)
- 트랜잭션의 시작과 끝을 지정하기 위한 명령을 포함합니다.
- 내장 SQL 및 동적 SQL (Embedded SQL and Dynamic SQL)
- SQL 문이 일반 목적 프로그래밍 언어(C/C++) 내에 어떻게 내장될 수 있는지를 정의합니다.
- 권한 부여 (Authorization)
- Relation 및 view에 대한 접근 권한을 지정하기 위한 명령을 포함합니다.
데이터 정의 언어 (Data Definition Language)
- SQL 데이터 정의 언어 (DDL)는 relation에 대한 정보를 명시(지정)하는 기능을 제공합니다.
- 포함되는 내용:
- 각 relation의 스키마
- 각 attribute와 관련된 값의 유형
- integrity constraints(무결성 제약 조건)
- 각 relation에 대해 유지해야 하는 인덱스 집합
- 각 relation에 대한 보안 및 authorization(권한 정보)
- 디스크에 있는 각 관계의 물리적 저장 구조
무결성 제약 조건 (Integrity Constraints)
- 무결성 제약 조건은 일련의 규칙입니다.
- 정보의 품질을 유지하기 위해 사용됩니다.
- 무결성 제약 조건은 데이터 삽입, 업데이트, 기타 프로세스가 데이터 무결성에 영향을 미치지 않도록 수행되도록 보장합니다.
- 따라서 무결성 제약 조건은 데이터베이스에 대한 우발적인 손상을 방지하기 위해 사용됩니다.

도메인 제약 조건 (Domain Constraints)
- 도메인 제약 조건은 attribute에 대한 유효한 값 집합의 정의로 정의될 수 있습니다.
- 도메인의 데이터 유형에는 string, character, integer, time, date, currency 등이 포함됩니다.
- attribute의 값은 해당 도메인에 있어야 합니다.

- Age 의 'A'는 허용되지 않음--> 나이(Age)는 integer attribute 입니다.
엔티티 무결성 제약 조건 (Entity Integrity Constraints)
- 엔티티 무결성 제약 조건은 기본 키 값이 null이 될 수 없음을 명시합니다.
- Primary key값은 relation의 개별 행을 식별하는 데 사용되며, primary key가 null 값을 가지면 해당 행을 식별할 수 없습니다.
- 테이블은 primary key 필드 외의 null 값을 포함할 수 있습니다.

- ID에 null 값은 허용되지 않음: Primary key에 해당하는 Attribute는 NULL 값을 가질 수 없습니다.
참조 무결성 제약 조건 (Referential Integrity Constraints)
- 참조 무결성 제약 조건은 두 테이블 간에 지정됩니다.
- 참조 무결성 제약 조건에서는 테이블 1의 foreign key(외래 키)가 테이블 2의 primary key(기본 키)를 참조하면 테이블 1의 foreign key의 모든 값은 null이거나 테이블 2에 있어야 합니다.

키 제약 조건 (Key Constraints)
- Key는 엔티티 집합 내에서 엔티티를 고유하게 식별하는 데 사용되는 엔티티 집합입니다.
- 엔티티 집합은 여러 키를 가질 수 있지만 그 중 하나는 기본 키가 됩니다.
- Primary key는 고유한 값을 포함할 수 있으며 관계형 테이블에서 NULL 값을 가질 수 없습니다.
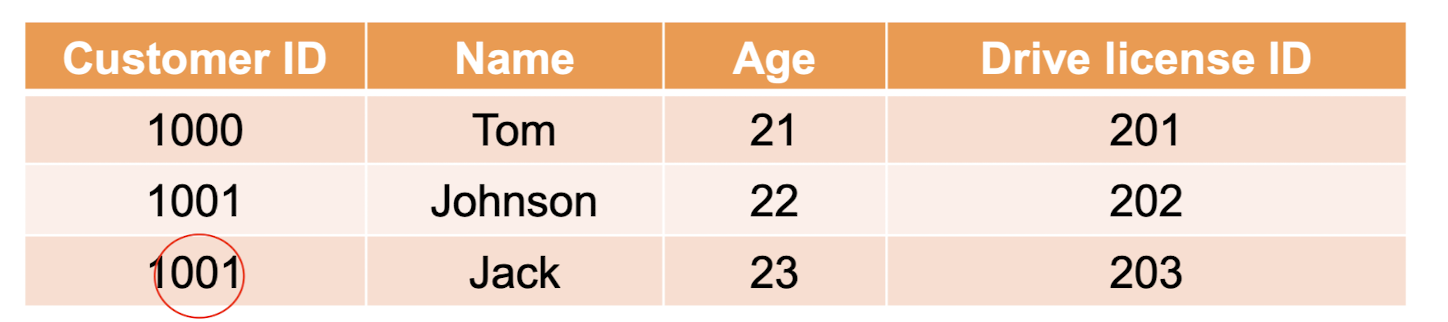
- Not allowed. entitiy set에서 Primary key의 값은 unique 해야 함
기본 키 (Primary Key)
- Primary key는 각 레코드에 대해 고유한 관계형 데이터베이스의 키입니다.
- 관계형 데이터베이스는 항상 하나의 Primary key를 가져야 합니다.
- Primary key는 일반적으로 관계형 데이터베이스 테이블의 열로 나타납니다.
Foreign Key (외래 키)
- Foreign key는 두 테이블 간의 데이터를 연결하는 관계형 데이터베이스 테이블의 attribute 집합입니다.
- Foreign key는 다른 테이블의 Primary key를 참조하므로 테이블 간의 참조 역할을 합니다.
- Foreign key는 다른 테이블에서 가져다 쓴다.
- Foreign key는 다른 테이블의 Primary key와 일치하는 값인 테이블의 속성입니다.
Foreign Key (외래 키) 예시 (1)
- 고객(Customer)과 연락처(Contact) 테이블

- Foreign Key를 사용했을 때 장점 : 데이터 저장에 사용되는 공간을 줄일 수 있고, Table Lock에 유리하다
Foreign Key (외래 키) 예시 (2)

SQL의 도메인 유형
- char(n): 사용자 지정 길이 n의 고정 길이 문자 문자열
- varchar(n): 사용자 지정 최대 길이 n의 가변 길이 문자 문자열
- int: 기계 종속적인(machine-dependent) 정수의 유한한 부분 집합
- smallint: 기계 종속적인 작은 정수의 부분 집합
- numeric(p, d): user-specified precision(사용자 지정 정밀도) p 자리와 소수점 오른쪽 d 자리를 가지는 고정 소수점 수 (예: numeric(3,1) 은 44.5를 정확하게 저장할 수 있지만 444.5 또는 0.32는 저장할 수 없음)
- real, double precision: 기계 종속적인 정밀도를 가지는 부동 소수점 수
- float(n): 최소 n 자릿수를 가지는 사용자 지정 정밀도의 부동 소수점 수
테이블 생성 구문
- SQL 관계는 create table 명령을 사용하여 정의됩니다:

- r은 relation의 이름입니다.
- 각 A_i는 relation r의 스키마에서 attribute 이름입니다.
- D_i는 attribute A_i의 도메인 값의 데이터 유형입니다.
예시:
create table instructor (
ID char(5),
name varchar(20),
dept_name varchar(20),
salary numeric(8,2)
)테이블 생성 시 무결성 제약 조건
- 무결성 제약 조건의 유형
- primary key (A1, ..., An)
- foreign key (Am, ..., An) references r
- not null
- SQL은 무결성 제약 조건을 위반하는 데이터베이스의 업데이트를 방지합니다.
예시:
create table instructor (
ID char(5),
name varchar(20) not null,
dept_name varchar(20),
salary numeric(8,2),
primary key (ID),
foreign key (dept_name) references department
);Relation Definitions
예시:
create table student (
ID varchar(5),
name varchar(20) not null,
dept_name varchar(20),
tot_cred numeric(3,0),
primary key (ID),
foreign key (dept_name) references department
);create table course (
course_id varchar(8),
title varchar(50),
dept_name varchar(20),
credits numeric(2,0),
primary key (course_id),
foreign key (dept_name) references department
);기본 쿼리 구조
- 일반적인 SQL 쿼리의 형식은 다음과 같습니다:

- A_i는 attribute를 나타냅니다.
- R_i는 relation를 나타냅니다.
- P는 조건문입니다.
- SQL 쿼리의 결과는 relation입니다.
SQL Select 사용 방법
SQL Select
- SQL Select 문은 데이터베이스에서 데이터를 검색하는 데 사용됩니다.
- 레코드를 가져옵니다.
- 데이터베이스에서 반환된 데이터는 결과 테이블에 저장됩니다.
SELECT column1, column2, ...
FROM table
WHERE condition;- SELECT: 표시할 열들
- FROM: 사용할 테이블
- WHERE: 조건을 만족하는 행들만 반환
SQL 일반 구문
SELECT column-names
FROM table-name;SQL Select 예시
SELECT *
FROM Employee;- 에스터리스크 '*'는 select 절에서 "모든 속성"을 나타냅니다.

SQL Select 사용 방법?
SQL Select 예시
- Employee 테이블에서 first name, father name, city & phone 선택
SELECT FirstName, FatherName, City, Phone
FROM Employee;결과

select 절
- select 절은 쿼리 결과에 원하는 속성들을 나열합니다.
- 관계 대수의 투영 연산(projection operation)에 해당합니다.
예시: 모든 강사의 이름을 찾기:
select name from instructor;- 참고: SQL 이름은 대소문자를 구분하지 않습니다 (즉, 대문자 또는 소문자를 사용할 수 있습니다).
- 예:
Name≡NAME≡name
- 예:
- SQL은 쿼리 결과에 중복을 허용합니다.
- 중복을 제거하려면 select 뒤에 distinct 키워드를 삽입합니다.
예시: 모든 강사의 부서 이름을 찾고 중복을 제거
select distinct dept_name from instructor;- all 키워드는 중복을 제거하지 않도록 지정합니다.
select all dept_name from instructor;from 절
- from 절은 쿼리에 포함된 관계를 나열합니다.
- 관계 대수의 카테시안 곱 연산(Cartesian product operation)에 해당합니다.
예시: 강사와 가르치는 강좌의 카티션 곱 찾기
select *
from instructor, teaches;- 모든 가능한 강사-강좌 쌍을 생성하며, 두 relation의 모든 attribute을 포함합니다.
- 공통 attribute(e.g., ID)에 대해, 결과 테이블의 attribute은 relation의 이름을 사용하여 이름이 변경됩니다 (e.g.,
instructor.ID).
카테시안 곱 (X) 상기시키기
- 두 relation의 정보를 결합할 수 있습니다.
- 두 relation의 모든 튜플 조합을 생성합니다.
- relation r1과 r2의 카테시안 곱은 r1 X r2로 나타냅니다.

예시
- 관계 R과 S의 카티션 곱

예시
- 강사 이름과 강좌 ID 찾기
select name, course_id from instructor, teaches where instructor.ID = teaches.ID;
예시
- 미술 부서의 모든 강사 이름과 강좌 ID 찾기
select name, course_id from instructor, teaches where instructor.ID = teaches.ID and instructor.dept_name = 'Art';
- 이 예시에서, 공급업체(suppliers)라는 테이블이 있습니다.

SELECT *
FROM suppliers
WHERE supplier_id < 400
ORDER BY city DESC;- 세 개의 레코드가 선택됩니다.

where 절
- where 절은 결과가 충족해야 하는 조건을 지정합니다.
- where 절은 SQL DML 문과 함께 사용되며, 다음 일반 형식을 갖습니다:
SQL-DML-Statement
FROM table_name
WHERE predicate;- 관계 대수(relational algebra)의 조건(predicative)에 해당합니다.
- where 절은 결과가 충족해야 하는 조건을 지정합니다.
- 관계 대수의 선택 조건(selection predicate)에 해당합니다.
예시: 컴퓨터 과학(Comp. Sci.) 부서의 모든 강사를 찾기
select name
from instructor
where dept_name = 'Comp. Sci.';- SQL은 논리 연산자 and, or, not을 사용할 수 있습니다.
- 논리 연산자의 피연산자는 <, <=, >, >=, =, <>와 같은 비교 연산자를 포함할 수 있습니다.
- 비교는 산술 표현의 결과에도 적용될 수 있습니다.
예시: 연봉이 80000 이상인 컴퓨터 과학 부서의 모든 강사를 찾기
select name
from instructor
where dept_name = 'Comp. Sci.' and salary > 80000;where 절 조건
- SQL은 between 비교 연산자를 포함합니다.
예시: 연봉이 $90,000에서 $100,000 사이인 모든 강사의 이름을 찾기 (즉, >= $90,000 그리고 <= $100,000)
select name
from instructor
where salary between 90000 and 100000;- 튜플 비교
예시
select name, course_id
from instructor, teaches
where (instructor.ID, dept_name) = (teaches.ID, 'Biology');튜플의 표시 순서 정렬
- 모든 강사의 이름을 알파벳 순서로 나열하기
select distinct name
from instructor
order by name;- 각 attribute에 대해 내림차순을 desc, 오름차순을 asc로 지정할 수 있습니다.
예시: 이름을 내림차순으로 정렬
order by name desc;
'LegacyPosts' 카테고리의 다른 글
| [DataBase] 05. E-R Model (0) | 2024.06.25 |
|---|---|
| [DataBase] 04. Intermediate SQL (0) | 2024.06.15 |
| [DataBase] 03. Introduction to SQL(2) (0) | 2024.06.15 |
| [DataBase] 02. Introduction to Relational Model (0) | 2024.06.15 |
| [DataBase] 01. Introduction (0) | 2024.06.15 |