관계형 모델 (Relational Model)
- 관계형 모델은 데이터베이스 관리에서 데이터 구조와 언어를 사용하여 데이터를 관리하는 접근 방식입니다.
- 모든 데이터는 튜플(tuple) 형태로 표현되며, relation으로 그룹화됩니다.
- 관계형 모델로 구성된 데이터베이스를 관계형 데이터베이스(relational database)라고 합니다.
- 관계형 모델의 목적은 데이터를 명시하고 쿼리를 지정하는 선언적 방법을 제공하는 것입니다.
- 사용자는 데이터베이스가 포함하는 정보와 원하는 정보를 직접 명시하며, 데이터베이스 관리 시스템 소프트웨어가 데이터를 저장하고 쿼리에 응답하기 위한 데이터 구조를 설명하는 과정을 담당합니다.
- modern DB(mySQL, ...)에서 사용되고 있다.
관계형 데이터 모델 (Relational Data Model)
- 관계형 데이터 모델은 데이터 저장 및 처리에 널리 사용되는 기본 데이터 모델입니다.
- 테이블 (Tables): 관계형 데이터 모델에서 relation(관계)는 테이블 형식으로 저장됩니다.
- 테이블은 행과 열로 구성되며, 행(rows)은 record를 나타내고 열(columns)은 attribute을 나타냅니다.
- 튜플 (Tuple): 테이블의 단일 행으로, 해당 relation의 단일 record를 포함하는 것을 튜플이라고 합니다

- Column(열)
- Column(열)은 특정 유형의 데이터 값을 모아 놓은 집합으로, 데이터베이스의 각 row(행)에 대한 값을 가집니다.
- Column(열)은 속성(attribute)이라고도 불립니다.
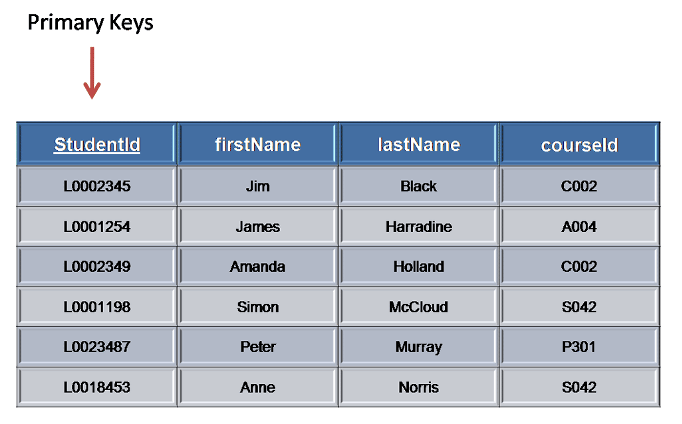
- Primary Key
- Primary Key는 각 레코드에 대해 고유한 관계형 모델의 key입니다.
- Domain
- 도메인은 column이 포함할 수 있는 허용 가능한 값의 집합입니다.
- 이는 column의 데이터 타입과 다양한 property에 기반합니다.
관계형 모델의 연산 (Operations in Relational Model)
- Insert Operation
- 새로운 튜플에 대한 속성 값을 제공하여 relation에 삽입됩니다.
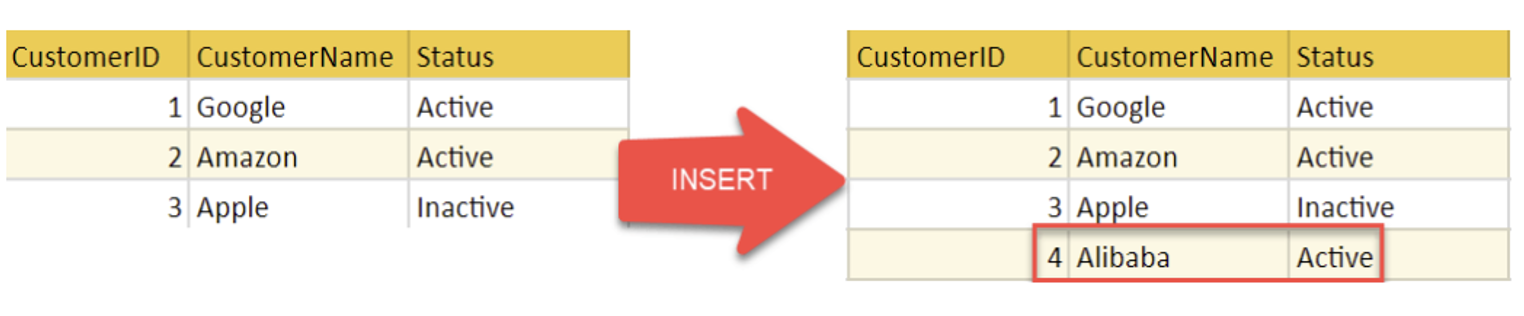
- Update Operation
- 기존 튜플의 속성 값을 수정합니다.

- Delete Operation
- 조건에 따라 튜플을 선택하여 삭제합니다.

- Select Operation
- 조건에 따라 튜플을 선택합니다.

관계형 모델의 예시 (Example of Relational Model)
- Ex) Instructor Relation
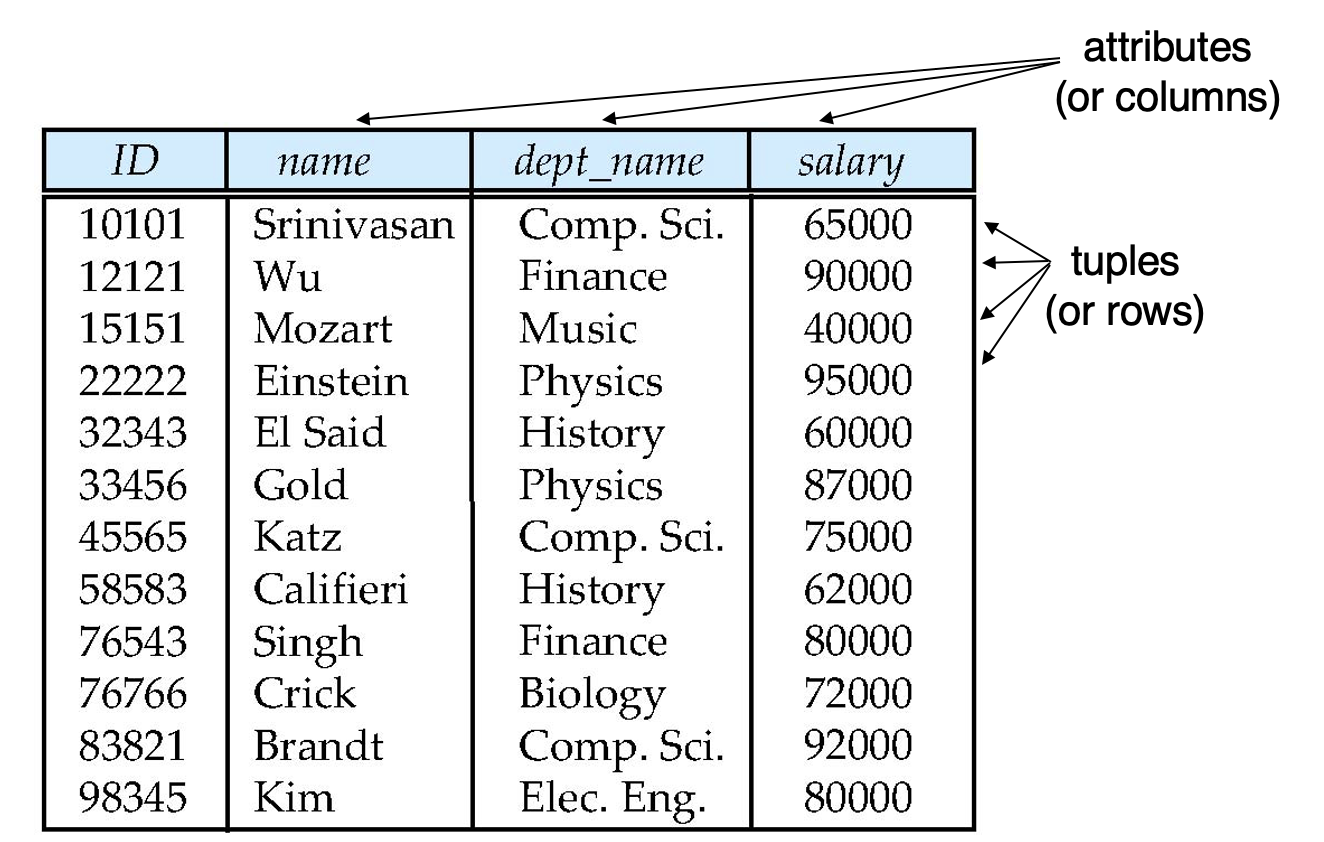
Relations are Unordered : Relation은 순서가 없다.
- 튜플의 순서는 중요하지 않습니다. 튜플은 임의의 순서로 저장될 수 있습니다.
- ex) 순서가 없는 튜플로 나타낸 Instructor relation

데이터베이스 스키마 (Database Schema)
- 데이터베이스 스키마 (Database Schema)
- 데이터베이스의 논리적 구조를 의미합니다.
- 데이터베이스 인스턴스 (Database Instance)
- 특정 시점에 데이터베이스에 있는 데이터의 스냅샷입니다.
- 인스턴스는 계속해서 변하지만, Schema는 그대로이다.
- 예시 (Example)
- 스키마: 강사 (ID, 이름, 부서명, 급여)
- 인스턴스

키 (Keys)
- Primary Keys(PK)
- PK는 각 레코드에 대해 고유한 관계형 데이터베이스의 키입니다. 이는 운전 면허 번호, 전화 번호(지역 코드 포함), 차량 식별 번호(VIN) 등과 같은 고유 식별자입니다.
- 관계형 데이터베이스는 하나의 PK만 가질 수 있습니다.
- 보통 PK는 관계형 DB Table에서 columns에 나타납니다
Schema Diagram for University Database

관계 대수 (Relational Algebra)
- 프로시저 언어(procedural language)로서, 하나 또는 두 개의 relation을 입력으로 받아 새로운 relation을 결과로 생성하는 일련의 연산으로 구성
- 여섯 가지 기본 연산자
- select: σ
- project: π
- 합집합 (union): ∪
- 차집합 (set difference): −
- 카테시안 곱 (Cartesian product): ×
Select Operation
- Select는 주어진 조건을 만족하는 튜플을 선택
- 표기법: σ_p(r)
- p는 선택 조건 (selection predicate)라고 부름
- 예: "물리학 (Physics)" 학과의 교수인 튜플을 선택
- 쿼리: σ_dept_name="Physics" (instructor)
- 결과:

- SELECT 연산은 주어진 선택 조건에 따라 튜플의 부분 집합을 선택
- 시그마 (σ) 기호로 표시
- 선택 조건을 충족하는 튜플을 선택하는 표현식으로 사용
- 선택 연산은 주어진 조건을 만족하는 튜플을 선택
- 표기법: σ_p(r)
- σ는 조건 (predicate)
- r은 관계 (relation) 이름
- p는 명제 논리 (prepositional logic)
- 조건 비교는 =, ≠, >, ≥, <, ≤ 사용 가능
- 여러 조건을 AND (∧), OR (∨), NOT (¬) 연결자로 결합 가능
- 예: 물리학 학과의 교수 중 급여가 90,000 이상인 교수 찾기
- 쿼리: σ_dept_name="Physics" ∧ salary > 90000 (instructor)
- 예: 건물 이름과 동일한 학과 이름을 가진 학과 찾기
- 쿼리: σ_dept_name=building (department)


Project Operation(투영 연산)
- 특정 속성(attributes)을 생략한 relation을 반환하는 단항 연산(unary operation, argument가 1개인 연산을 말함)

- 표기법: π_A1, A2, ..., Ak (r)
- A1, A2는 속성 이름, r은 관계 이름
- 결과는 나열된 attribute의 relation으로 정의되며 나열되지 않은 속성은 삭제
- 중복 행은 제거됨, relation은 집합(set)이기 때문
- 예: 교수의 dept_name 속성 제거
- 쿼리:
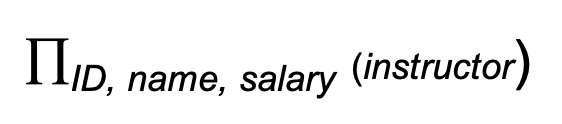
- 결과

관계 연산의 조합 (Composition of Relational Operations)
- 관계 대수 연산의 결과는 relation이며, 따라서 관계 대수 연산은 관계 대수 표현으로 조합 가능
- 예: 물리학 학과의 교수 이름 찾기
- 쿼리: π_name (σ_dept_name = "Physics" (instructor))

- Project operation(π)의 인수로 관계 이름 대신 표현식(σ_dept_name = "Physics" (instructor)을 사용
카테시안 곱 연산 (Cartesian-Product Operation)
- 카테시안 곱 연산 (×)은 두 relation(관계)의 모든 가능한 튜플 쌍을 결합
- 예: instructor와 teaches 관계의 카테시안 곱
- 표기법: instructor × teaches
- 우리는 가능한 각 튜플 쌍에서 결과의 튜플을 구성합니다. 하나는 instructor relation에서, 다른 하나는 teaches relation에서
- instructor ID는 두 relation 모두에 나타나기 때문에, relation의 이름에 attribute을 첨부하여 이러한 attribute을 구별합니다.
- 예:
- instructor.ID
- teaches.ID
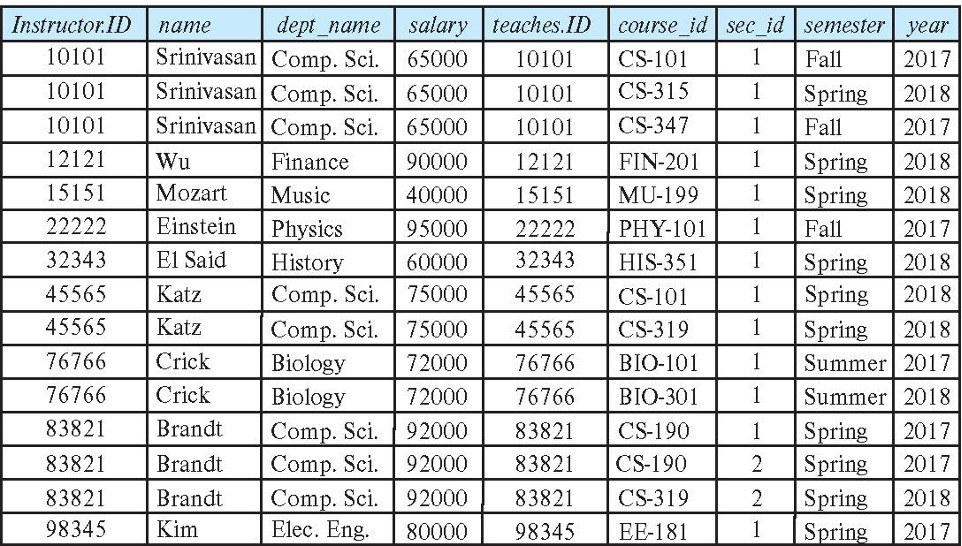
instructor × teaches 테이블


Join Operation
- 카테시안 곱 instructor × teaches는 모든 가능한 튜플 쌍을 생성
- 대부분의 결과 행은 특정 과목을 가르치지 않는 교수 정보 포함

- "instructor × teaches" 중 교수와 그들이 가르치는 과목에 해당하는 튜플만 얻기 위해 위와 같이 사용한다.
- 우리는 교수와 그들이 가르치는 과목에 해당하는 튜플만 얻을 수 있음
- 테이블 대응:
- Join 연산은 Select 연산과 카테시안 곱 연산을 단일 연산으로 결합 가능
- r(R)과 s(S) relation를 고려
- "theta"를 스키마 R과 S의 속성에 대한 조건으로 설정

- 따라서:
- σ_instructor.id = teaches.id (instructor × teaches)
- 동일하게 다음으로 표현 가능:

Union Operation(합집합 연산)
- Union Operation은 두 relation을 결합
- 표기법: r ∪ s
- r ∪ s가 유효하려면:
- r과 s는 동일한 수의 attribute을 가져야 함
- attribute 도메인이 호환되어야 함(must be compatible) (예: r의 두 번째 열은 s의 두 번째 열과 동일한 유형의 값을 처리)
- 예: 2017년 가을 학기 또는 2018년 봄 학기 또는 두 학기 모두에 가르친 모든 과목 찾기


Set-Intersection Operation(교집합 연산)
- Set-Intersection 연산은 두 input relation 모두에 존재하는 튜플을 찾음
- 표기법: r ∩ s
- 가정:
- r과 s는 동일한 수의 도메인을 가짐
- r과 s의 attribute는 호환됨
- 예: 2017년 가을 학기와 2018년 봄 학기 모두에 가르친 모든 과목 찾기
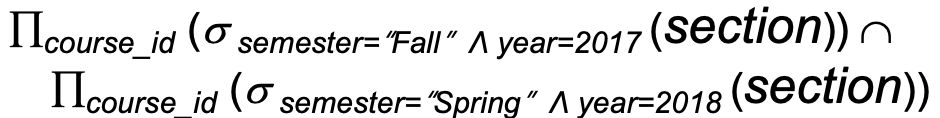
- 결과:

Set Difference Operation(차집합 연산)
- Set Difference Operation은 한 relation에 있지만 다른 relation에 없는 튜플을 찾음
- 표기법: r - s
- r - s 와 s - r의 결과는 같지 않음에 주의하자.
- Set Difference는 호환되는 relation 간에 수행되어야 함
- r과 s는 동일한 arity를 가져야 함
- r과 s의 attribute 도메인은 호환되어야 함
- 예: 2017년 가을 학기에는 가르쳤지만 2018년 봄 학기에는 가르치지 않은 모든 과목 찾기

- 결과:

'LegacyPosts' 카테고리의 다른 글
| [DataBase] 05. E-R Model (0) | 2024.06.25 |
|---|---|
| [DataBase] 04. Intermediate SQL (0) | 2024.06.15 |
| [DataBase] 03. Introduction to SQL(2) (0) | 2024.06.15 |
| [DataBase] 03. Introduction to SQL(1) (0) | 2024.06.15 |
| [DataBase] 01. Introduction (0) | 2024.06.15 |