Motivation
- 매우 대량의 데이터 수집
- 웹, 소셜 미디어, 최근에는 사물인터넷의 성장에 의해 주도됨
- 웹 로그는 초기 데이터 소스였음
- 웹 로그에 대한 분석은 광고, 웹 사이트 구조화, 사용자에게 표시할 게시물 등에 큰 가치를 가짐
- 빅 데이터: 이전 세대 데이터베이스와 구별됨
- 볼륨: 저장된 데이터의 양이 훨씬 큼
- 속도: 삽입 속도가 훨씬 높음
- 다양성: 관계형 데이터를 넘어 다양한 유형의 데이터 포함
Querying Big Data
- 매우 높은 scalability(확장성)이 필요한 트랜잭션 처리 시스템
- 많은 애플리케이션이 매우 높은 확장성을 얻을 수 있다면 ACID 속성 및 기타 데이터베이스 기능을 기꺼이 포기함
- 매우 높은 확장성과 비관계형 데이터를 지원해야 하는 쿼리 처리 시스템
Big Data Storage Systems
- 데이터베이스의 역할 감소
- 데이터 읽기/쓰기 역할 증대
- 분산 파일 시스템
- 여러 데이터베이스에 걸친 Sharding
- Key-value 스토리지 시스템
- 병렬 및 분산 데이터베이스
Hadoop File System Architecture
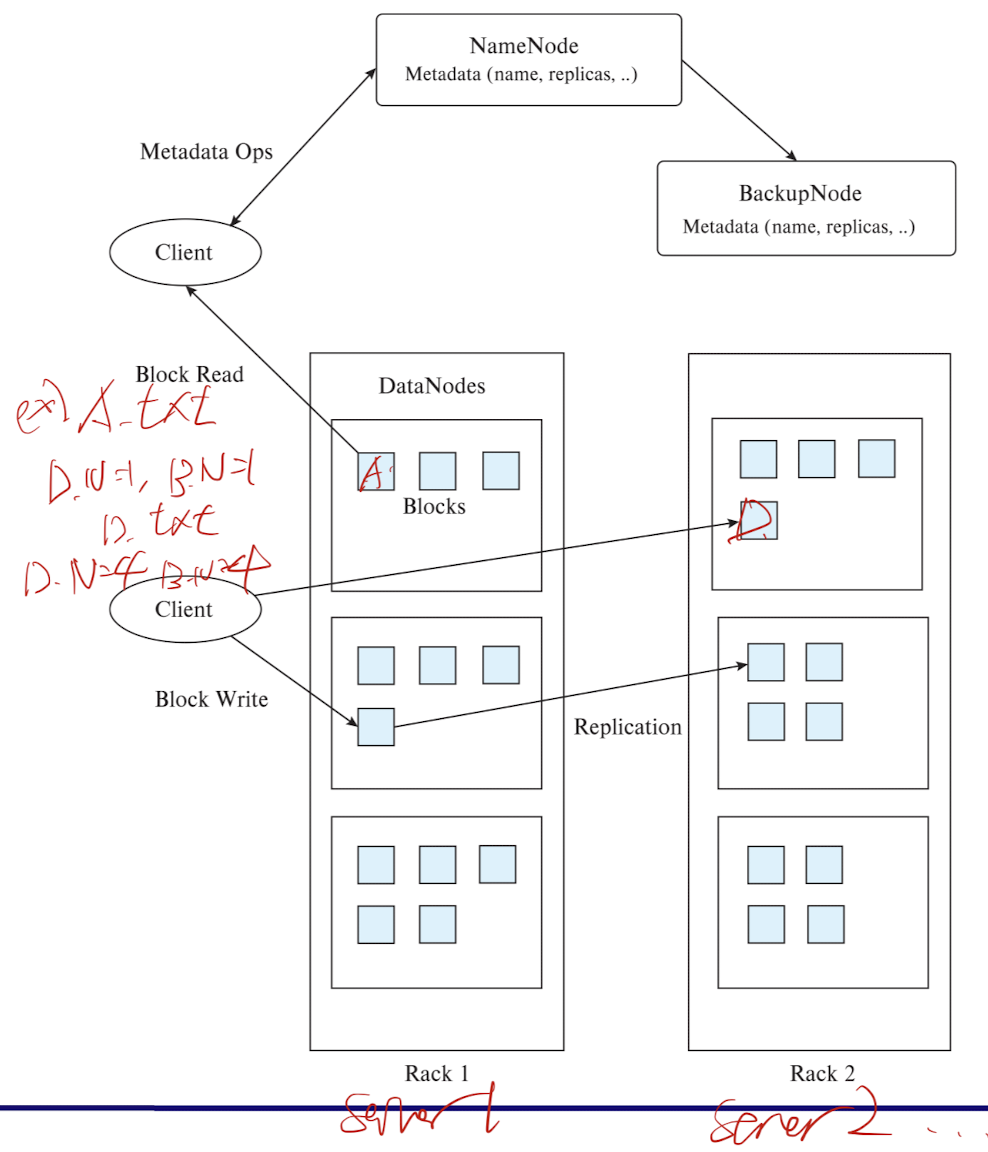
- 클러스터 전체에 단일 네임스페이스
- 파일은 블록으로 분할됨
- 일반적으로 64MB 블록 크기
- 각 블록은 여러 데이터노드에 복제됨
- 클라이언트
- 네임노드에서 블록의 위치를 찾음
- 데이터노드에서 직접 데이터에 접근
Hadoop Distributed File System (HDFS)
- 네임노드
- 파일 이름을 블록 ID 목록에 매핑
- 각 블록 ID를 해당 블록의 복사본을 포함하는 데이터노드에 매핑
- 데이터노드: 블록 ID를 디스크의 물리적 위치에 매핑
- Data Coherency(데이터 일관성)
- Write-once-read-many access 모델
- 클라이언트는 기존 파일에만 추가할 수 있음
- 수백만 개의 대형 파일에 적합한 분산 파일 시스템
- 그러나 수십억 개의 작은 튜플과 함께 성능이 좋지 않음
Sharding
- Sharding: 여러 데이터베이스에 데이터를 분할
- 데이터 베이스의 테이블을 특정 기준에 따라 여러 파티션(또는 샤드)로 나눈다. 이 기준을 일반적으로partitioning attributes(partitioning keys 또는 shard keys라고도 함. 예: 사용자 ID
- 예: 데이터베이스 1에서 키 값이 1에서 100,000인 레코드, 데이터베이스 2에서 키 값이 100,001에서 200,000인 레코드
- 애플리케이션은 각 데이터베이스에서 어느 레코드가 있는지 추적하고 해당 데이터베이스로 쿼리/업데이트를 보냄
- 긍정적 측면: 확장성이 좋고 구현이 쉬움(+ 병렬 처리가 가능하여 처리량 향상)
- 부정적 측면:
- Not transparent(투명하지 않음): 애플리케이션이 여러 데이터베이스에 걸친 쿼리, 쿼리 라우팅을 직접 처리해야 함
- 데이터베이스가 과부하되면 해당 load의 일부를 이동하는 것이 쉽지 않음
- 데이터베이스가 많아질수록 failure 가능성 증가
- 가용성을 보장하기 위해 복제본을 유지해야 하므로 애플리케이션의 작업이 증가
Sharding (e.g., Range Partitioning)
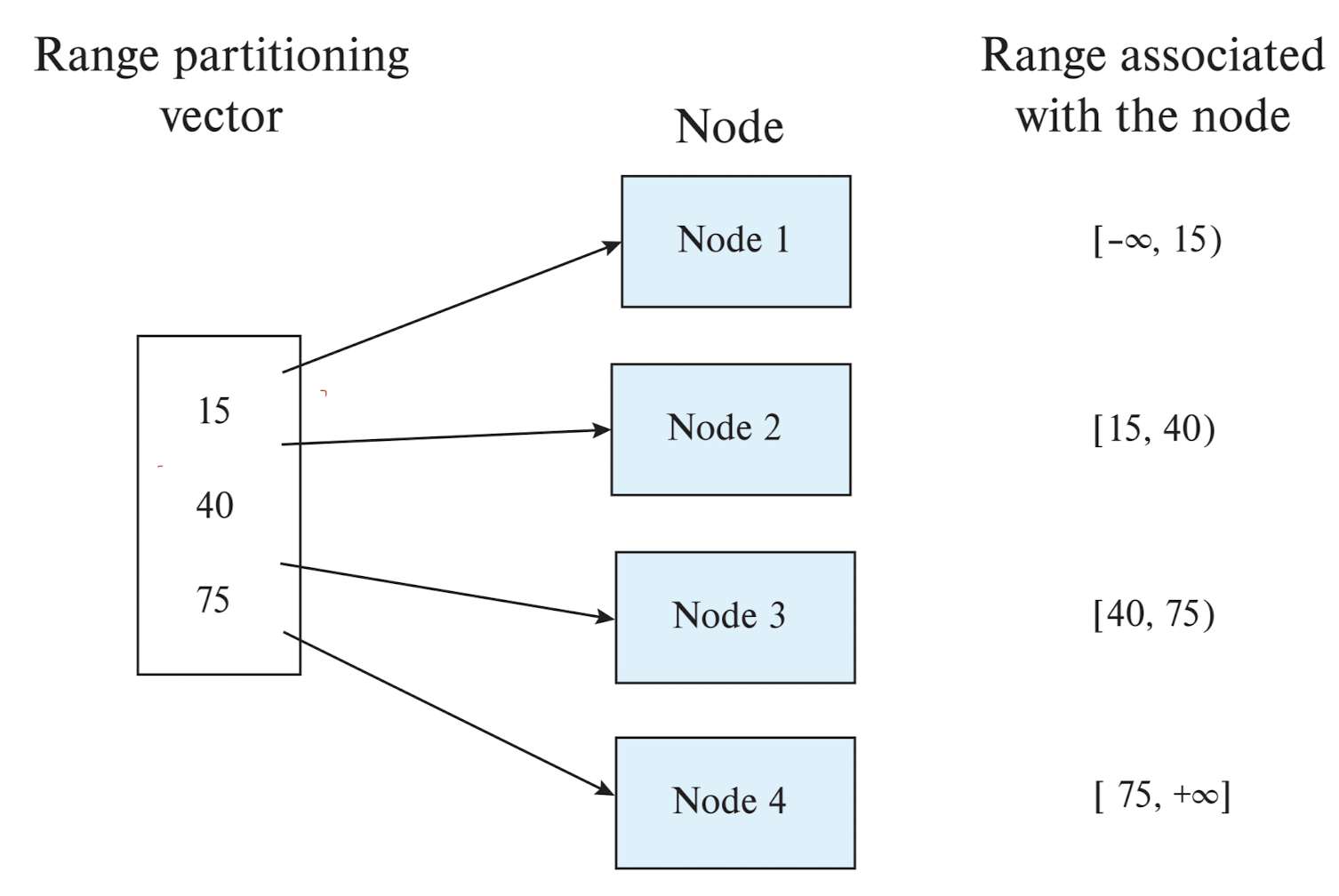
Simple Problem
- Challenge
- 1부터 10¹⁰까지 소수 출력

- 작업을 고르게 분할
- 각 스레드는 10⁹ 범위를 테스트
Types of Skew(왜곡의 유형)
- Data-distribution skew: 일부 노드는 많은 튜플을 갖는 반면, 다른 노드는 적은 튜플을 가질 수 있음
- Data-distribution skew는 balanced range-partitioning vector를 생성하여 범위 분할로 피할 수 있음
- 현재 분할이 정적이라고 가정, 즉 분할 벡터가 한 번 생성되고 변경되지 않음
- 모든 변경은 재분할 필요
- 동적 분할은 분할 벡터를 연속적으로 변경할 수 있음
- 이에 대해서는 나중에 더 설명
Dynamic Repartitioning
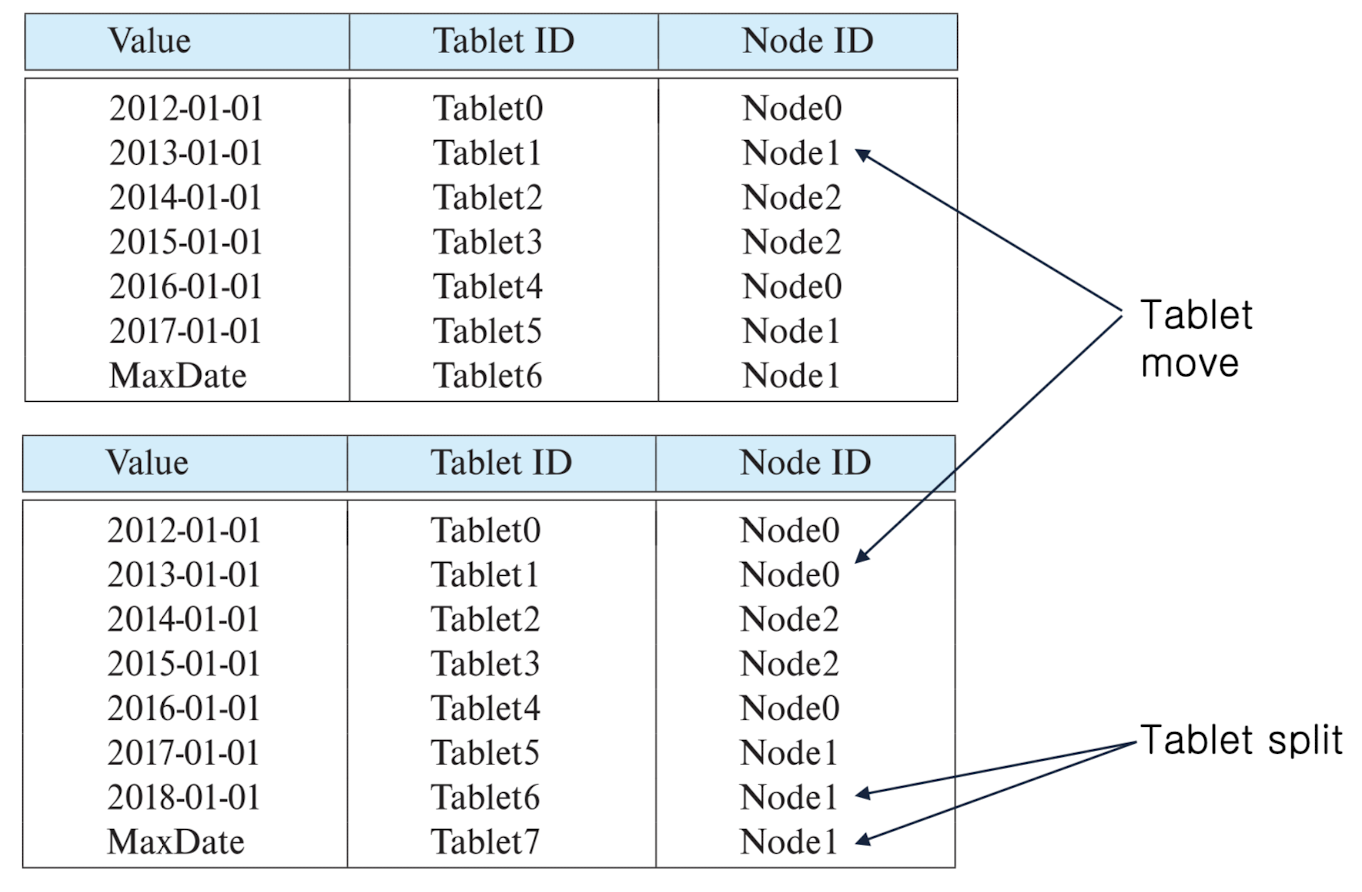
Replication (복제)
- 목표: 장애에도 불구하고 가용성 보장
- 데이터는 2개, 보통 3개의 노드에 복제됨
- 복제 단위는 일반적으로 파티션 (tablet)
- 장애가 발생한 노드의 데이터 요청은 자동으로 복제본으로 라우팅됨
- 각 tablet이 두 노드에 복제된 파티션 테이블

Basics: Data Replication (기본: 데이터 복제)
- 복제본의 위치
- 데이터 센터 내 복제
- 기기 장애 처리
- 로컬 기기에 복제본이 있으면 지연 시간 감소
- rack내에서, 또는 rack 간 복제
- 데이터 센터 간 복제
- 데이터 센터 장애(정전, 화재, 지진 등) 및 전체 데이터 센터의 네트워크 분할 처리
- 가까운 데이터 센터에 복제본이 있으면 최종 사용자에게 더 낮은 지연 시간 제공
- 데이터 센터 내 복제
Key Value Storage Systems
- Also-known-as
- KV store
- Key value database
- 대규모 데이터 세트의 빠른 처리를 위해 SQL 포기
- key-value storage system은 작은 (KB-MB) 크기의 대량 (수십억 개 이상의) 기록을 저장
- Records는 여러 기기에 파티션됨
- 쿼리는 시스템에 의해 적절한 기기로 라우팅됨
- Records는 또한 여러 기기에 복제되어 기기 장애 시에도 가용성 보장
- key-value storage system은 업데이트가 모든 복제본에 적용되어 값이 일관되도록 보장
- key-value storage system은 다음과 같은 것들을 저장할 수 있다
- uninterpreted bytes with an associated key (바이트 기반 키-값 저장소)
- 예: Amazon S3, Amazon Dynamo
- 연결된 key가 있는 wide-table 기반 저장소(임의의 수의 속성을 가진 와이드 테이블 형태로 저장)
- Google BigTable, Apache Cassandra, Apache Hbase, Amazon DynamoDB
- 일부 작업 (예: 필터링)을 저장소 노드에서 실행 가능
- JSON
- MongoDB, CouchDB (document model)
- uninterpreted bytes with an associated key (바이트 기반 키-값 저장소)
- 문서 저장소는 반구조적 데이터를 저장하며, 일반적으로 JSON
- 일부 key-value storage system은 타임스탬프/버전 번호와 함께 여러 버전의 데이터를 지원
Data type (Relational VS noSQL)
- Relational (관계형)
- SQL Databases
- 분석 (OLAP)
- Non-SQL Databases (비-SQL 데이터베이스)
- Key-Value
- Column-Family
- Graph
- Document
Key Value Storage Systems
- Key Value Storage System은 다음 기능을 지원한다
- put(key, value): 관련 키와 함께 값을 저장하는 데 사용
- get(key): 지정된 키와 관련된 저장된 값을 검색
- delete(key): 키 및 관련 값을 제거
- 일부 시스템은 키 값에 대한 범위 쿼리도 지원
- Key Value Storage System은 완전한 데이터베이스 시스템이 아님
- 트랜잭션 업데이트에 대한 지원 없음/제한적
- 응용 프로그램은 자체적으로 쿼리 처리를 관리해야 함
- 위의 기능을 지원하지 않으면 확장 가능한 데이터 저장 시스템을 구축하기 쉬워짐
- NoSQL 시스템이라고도 함
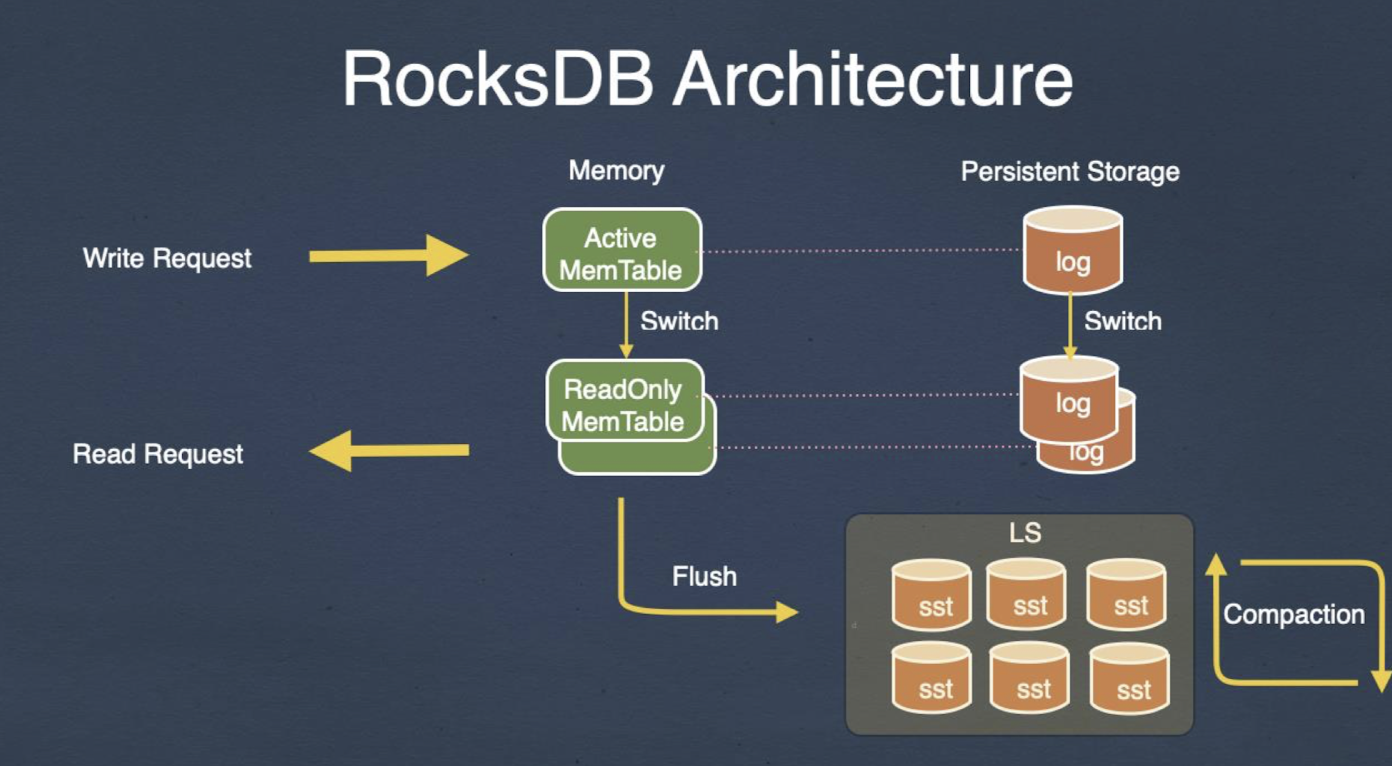
Internals of KV store (KV 저장소 내부 구조)
- RocksDB: 페이스북에서 개발 및 유지 관리
- 단순한 아키텍처
- HW에 대한 완전한 제어
Centralized Database Systems (중앙 집중식 데이터베이스 시스템)
- 단일 컴퓨터 시스템에서 실행
- 단일 사용자 시스템
- 다중 사용자 시스템은 서버 시스템으로도 알려져 있음
- 클라이언트 시스템에서 서비스 요청 수신
- 대규모 병렬 처리를 위한 다중 코어 시스템
- 일반적으로 몇 개에서 수십 개의 프로세서 코어
- 대조적으로, 세분화된 병렬 처리는 매우 많은 수의 컴퓨터 사용
Server System Architecture (서버 시스템 아키텍처)
- 서버 시스템은 크게 두 가지로 분류될 수 있음
- 트랜잭션 서버
- 관계형 데이터베이스 시스템에서 널리 사용
- 데이터 서버
- 고성능 트랜잭션 처리 시스템을 구현하는 병렬 데이터 서버
- 트랜잭션 서버
Transaction Servers (트랜잭션 서버)
- query server systems 또는 SQL server systems라고도 함
- 클라이언트가 서버에 요청을 보냄
- 트랜잭션이 서버에서 실행됨
- 결과가 클라이언트로 전송됨
Transaction System Processes
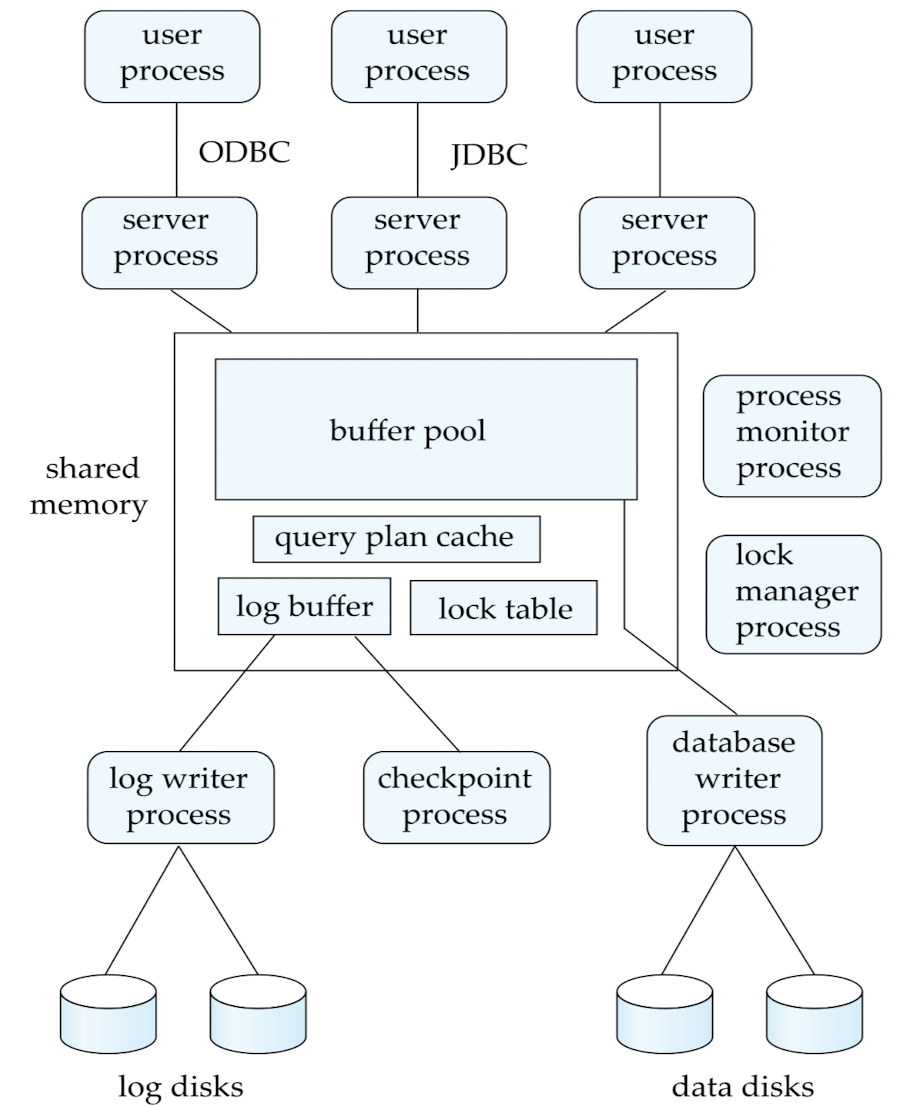
Transaction Server Process Structure
- 일반적인 트랜잭션 서버는 공유 메모리에서 데이터를 액세스하는 여러 프로세스로 구성됨
- 공유 메모리는 공유 데이터 포함
- Buffer pool
- Lock table
- Log buffer
- Cached qurey plans (같은 쿼리가 다시 제출될 경우 재사용)
- 모든 데이터베이스 프로세스는 공유 메모리에 접근 가능
- 서버 프로세스
- 사용자 쿼리(트랜잭션)를 받아 실행하고 결과를 반환
- 프로세스는 멀티스레드일 수 있으며, 단일 프로세스가 여러 사용자 쿼리를 동시에 실행할 수 있음
- 일반적으로 여러 멀티스레드 서버 프로세스 사용
- Database writer process
- 수정된 버퍼 블록을 지속적으로 디스크에 출력
- Log writer process
- 서버 프로세스는 단순히 로그 레코드를 로그 레코드 버퍼에 추가
- 로그 기록 프로세스는 로그 레코드를 안정적인 저장소에 출력
- Checkpoint process
- 주기적인 체크포인트 수행
- Process monitor process
- 다른 프로세스를 모니터링하고, 다른 프로세스가 실패하면 복구 조치 수행
- 예: 서버 프로세스가 실행 중인 트랜잭션 중단 및 재시작
- 다른 프로세스를 모니터링하고, 다른 프로세스가 실패하면 복구 조치 수행
- Lock manager process
- lock 요청/승인에 대한 프로세스 간 통신 오버헤드를 피하기 위해 각 데이터베이스 프로세스는 직접 lock 테이블에서 작업
- 대신, lock manager 프로세스에 요청을 보내지 않음
- 여전히 데드락 감지를 위해 lock manager 프로세스 사용
- lock 요청/승인에 대한 프로세스 간 통신 오버헤드를 피하기 위해 각 데이터베이스 프로세스는 직접 lock 테이블에서 작업
- 두 프로세스가 동시에 동일한 데이터 구조에 접근하지 않도록 하기 위해, 데이터베이스 시스템은 mutual exclusion을 구현
- Atomic instructions
- Test-And-Set
- Compare-And-Swap (CAS)
- 운영 체제 세마포어(semaphore)
- Atomic instructions보다 더 높은 오버헤드
- Atomic instructions
Data Servers/Data Storage Systems
- 데이터 항목은 처리가 수행되는 클라이언트로 전송됨
- 업데이트된 데이터 항목은 서버에 다시 작성됨
- 이전 세대의 데이터 서버는 데이터 항목 단위 또는 여러 데이터 항목을 포함하는 페이지 단위로 작동
- 현재 세대의 데이터 서버 (데이터 저장 시스템이라고도 함)는 데이터 항목 단위로만 작업
- 일반적으로 사용되는 데이터 항목 형식은 JSON, XML 또는 단순히 해석되지 않은 이진 문자열 포함
- Prefetching
- 곧 사용할 수 있는 항목을 미리 가져옴
- Data caching
- 캐시 일관성 유지
- Lock caching
- Lock은 트랜잭션 간에 클라이언트에 의해 캐시될 수 있음
- Lock은 서버에 의해 다시 호출될 수 있음
- Adaptive lock granularity(적응형 lock 적용도)
- Lock granularity escalation(락 세분화 높이기)
- 더 세분화된 granularity (예: tuple) lock에서 더 거친 lock으로 전환
- Lock granularity de-escalation(락 세분화 낮추기)
- 초기에는 거친 granularity로 시작하여 오버헤드를 줄이고, 서버에서 더 많은 동시성 충돌이 발생할 경우 더 세분화된 granularity로 전환
- 자세한 내용은 책 참조
- Lock granularity escalation(락 세분화 높이기)
Parallel Systems
- 병렬 데이터베이스 시스템은 빠른 상호 연결 네트워크로 연결된 여러 프로세서 및 여러 디스크로 구성됨
- Motivation: 단일 컴퓨터 시스템이 처리할 수 없는 워크로드 처리
- 고성능 트랜잭션 처리
- 예: 웹 규모의 사용자 요청 처리
- 의사결정 지원
- 예: 대규모 웹 사이트/앱에서 수집된 데이터
Parallel Database Architectures

'DataBase > LegacyPosts' 카테고리의 다른 글
| [DataBase] 10. Normalization(정규화) (0) | 2024.06.26 |
|---|---|
| [DataBase] 08. Transaction Recovery (0) | 2024.06.26 |
| [DataBase] 07. Data Storage Structure (0) | 2024.06.25 |
| [DataBase] 06. Physical Storage System (0) | 2024.06.25 |
| [DataBase] 05. E-R Model (0) | 2024.06.25 |