Transaction
- Transaction은 여러 데이터 항목을 액세스하고 업데이트할 수 있는 프로그램 실행 단위(Unit)입니다.
- 예: 계정 A에서 계정 B로 $50을 이체하는 Transaction:
- read(A)
- A := A - 50
- write(A)
- read(B)
- B := B + 50
- write(B)
- 예: 계정 A에서 계정 B로 $50을 이체하는 Transaction:
- 처리해야 할 두 가지 주요 문제:
- 하드웨어 고장 및 시스템 충돌과 같은 다양한 종류의 failure(드뭄)
- 여러 Transaction의 동시 실행(자주 발생)
Example of Fund Transfer

- Atomicity requirement
- Transaction이 3단계 후에 failure하고 6단계 전에 failure하면 돈이 "잃어버린" 상태가 되어 일관성이 없는 데이터베이스 상태가 됩니다.
- failure는 소프트웨어 또는 하드웨어 때문일 수 있습니다.
- 시스템은 부분적으로 실행된 Transaction의 업데이트가 데이터베이스에 반영되지 않도록 해야 합니다.
- Durability requirement — 사용자가 Transaction이 완료되었다는 통지를 받은 후 (즉, $50 이체가 이루어진 후), Transaction에 의한 데이터베이스의 업데이트는 소프트웨어나 하드웨어 failure가 있어도 유지되어야 합니다.
- Consistency requirement in above example:
- A와 B의 합계는 Transaction의 실행에 의해 변경되지 않습니다.
- (1번 이전과 6번 이후의 A + B가 동일해야 한다)
- 일반적으로 Consistency requirement은 다음을 포함합니다.
- Transaction은 일관된 데이터베이스를 봐야 합니다.
- Transaction 실행 중 데이터베이스는 일시적으로 일관성이 없을 수 있습니다.
- Transaction이 성공적으로 완료되면 데이터베이스는 일관성을 유지해야 합니다.
- Isolation requirement — 3단계와 6단계 사이에 다른 Transaction T2가 부분적으로 업데이트된 데이터베이스에 액세스할 수 있으면 일관성이 없는 데이터베이스를 볼 수 있습니다 (A + B의 합계가 예상보다 적음).
- Isolation은 Transaction을 순차적으로 실행하여 쉽게 보장할 수 있습니다.
- 즉, 하나씩 순차적으로 실행합니다.
- Isolation은 Transaction을 순차적으로 실행하여 쉽게 보장할 수 있습니다.
ACID Properties(중요!)
- Transaction은 여러 데이터 항목을 액세스하고 업데이트할 수 있는 프로그램 실행 단위입니다. 데이터의 무결성을 유지하기 위해 데이터베이스 시스템은 다음을 보장해야 합니다:
- Atomicity. Transaction의 모든 작업이 올바르게 데이터베이스에 반영되거나 하나도 반영되지 않아야 합니다.
- Consistency. Transaction의 실행은 데이터베이스의 일관성을 유지합니다.
- (위 예시에서 1, 2, 3 만 실행되었다면, 반드시 consistency를 보장해야함)
- Isolation. 비록 많은 Transaction이 동시에 실행되지만, 각 transaction은 동시에 실행되는 transaction 서로를 몰라야 한다. 중간 transaction 결과는 동시에 실행되는 transaction들로부터 숨겨져야 한다. 모든 트랜잭션 Ti, Tj쌍에 대해 Ti가 실행을 시작하기 전에 Tj가 이미 실행을 완료했거나, Ti가 실행을 완료한 후에 Tj가 시작한 것 처럼 보여야 한다는 것 (각 트랜잭션이 다른 트랜잭션의 중간 결과를 인식하지 못하도록 하고, 서로 간섭하지 않도록 하는 원칙)
- Durability. Transaction이 성공적으로 완료된 후에는 데이터베이스에 대한 변경 사항이 시스템 failure가 발생하더라도 유지되어야 합니다.
Transaction State
- Active – 초기 상태; Transaction이 실행되는 동안 이 상태에 있습니다.
- Partially committed – final statement가 실행된 직후. (어떤 query도 transaction에 included 될 수 없는 상태)
- Failed – 정상 실행이 더 이상 진행될 수 없다는 것을 발견한 이후 상태
- Aborted – Transaction이 롤백되고 데이터베이스가 Transaction 시작 전 상태로 복원된 후. Transaction이 중단된 후 두 가지 선택 사항:
- Transaction을 다시 시작
- 내부 논리적 오류가 없는 경우에만 가능
- Transaction 중단
- Transaction을 다시 시작
- Committed – 성공적으로 완료된 후.
Failure Classification
- Transaction failure:
- Logical errors: 내부 오류 조건으로 인해 transaction cannot complete (ex. bad query)
- System errors: 오류 조건 (예: 교착 상태)으로 인해 데이터베이스 시스템이 active transaction을 종료해야 함
- System crash: 전원 장애 또는 기타 하드웨어 또는 소프트웨어 장애로 시스템이 충돌함.
- Fail-stop assumption: 비휘발성 저장소 내용이 시스템 충돌로 인해 손상되지 않았다고 가정한다
- 데이터베이스 시스템은 디스크 데이터 손상을 방지하기 위해 여러 무결성 검사를 수행합니다.
- Fail-stop assumption: 비휘발성 저장소 내용이 시스템 충돌로 인해 손상되지 않았다고 가정한다
- Disk failure: 헤드 충돌 또는 유사한 디스크 장애로 인해 디스크 저장소의 일부 또는 전부가 손상됨
- 파괴는 감지 가능한 것으로 가정: 디스크 드라이브는 Checksum을 사용하여 failure를 감지
Recovery Algorithms
- 예를 들어, Transaction T_i가 계정 A에서 계정 B로 $50을 이체한다고 가정
- 두 업데이트: A에서 50을 빼고 B에 50을 더합니다.
- Recovery 알고리즘은 두 부분으로 나뉩니다:
- failure로부터 Recovery할 수 있는 충분한 정보가 존재하도록 보장하기 위해 정상 Transaction 처리 중 수행되는 작업
- failure 후 데이터베이스 내용을 atomicity, consistency and durability를 보장하는 상태로 Recovery하기 위해 수행되는 작업
Recovery at Storage Level
- Volatile storage:
- system crash를 견디지 못함
- 예: 주 메모리, 캐시 메모리
- Nonvolatile storage:
- system crash를 견딤
- 예: 디스크, 테이프, 플래시 메모리, 비휘발성 RAM
- 하지만 여전히 failure할 수 있어 데이터 손실이 발생할 수 있음
- Stable storage:
- 모든 failure를 견디는 신화적인 형태의 저장소
- 비휘발성 매체의 여러 복사본을 유지하여 근사적으로 구현
- 안정된 저장소 구현에 대한 자세한 내용은 책을 참조하세요
Stable-Storage Implementation
- 각 블록의 여러 복사본을 별도의 디스크에 유지
- 복사본은 화재 또는 홍수와 같은 재해로부터 보호하기 위해 remote sites에 있을 수 있습니다.
- failure로부터 Recovery하기 위해:
- 먼저 일관성이 없는 블록을 찾기:
- 비용이 많이 드는 솔루션: 모든 디스크 블록의 두 복사본을 비교.
- 더 나은 솔루션:
- 비휘발성 저장소(플래시, 비휘발성 RAM 또는 디스크의 특수 영역)에 진행 중인 디스크 쓰기 기록.
- Recovery 중 이 정보를 사용하여 일관성이 없을 수 있는 블록을 찾고 이러한 블록의 복사본만 비교.
- 하드웨어 RAID 시스템에서 사용됨
- 불일치 블록의 두 복사본 중 하나에 오류(잘못된 체크섬)가 감지되면 다른 복사본으로 덮어씁니다. 두 복사본 모두 오류가 없지만 서로 다른 경우 첫 번째 복사본으로 두 번째 블록을 덮어씁니다.
- 먼저 일관성이 없는 블록을 찾기:
- 데이터 전송 중 failure는 여전히 일관성이 없는 복사본을 초래할 수 있음: 블록 전송은 다음과 같은 결과를 초래할 수 있음
- 성공적인 완료
- Partial failure: 대상 블록에 잘못된 정보가 있음
- Total failure: 대상 블록이 업데이트되지 않음
- 데이터 전송 중 failure로부터 저장 매체 보호(한 가지 솔루션):
- (각 블록의 두 복사본을 가정하여) 다음과 같이 output 작업을 실행:
- 첫 번째 물리적 블록에 정보를 기록합니다.
- 첫 번째 기록이 성공적으로 완료되면 동일한 정보를 두 번째 물리적 블록에 기록합니다.
- 두 번째 기록이 성공적으로 완료된 후에만 output이 완료됩니다.
- (각 블록의 두 복사본을 가정하여) 다음과 같이 output 작업을 실행:
(부연 설명: 첫 번째 블록에 쓰기 중에 문제가 발생하더라도, 두 번째 블록에도 동일한 정보가 복사되어 있어 데이터 손실을 방지할 수 있다. 최종적으로 두 번째 블록에 데이터가 성공적으로 기록되어야만 전체 output이 완료된다.)
Recovery and Atomicity
- 데이터 전송 중 failure로부터 저장 매체 보호(HW 솔루션):
- SSD에 슈퍼 커패시터(Supercapacitor)를 추가합니다.

Recovery and Atomicity
- 데이터 전송 중 failure로부터 저장 매체 보호(SW 솔루션):
- (각 블록의 두 복사본을 가정하여) 다음과 같이 output 작업을 실행:
- 첫 번째 물리적 블록에 정보를 기록합니다.
- 첫 번째 기록이 성공적으로 완료되면 동일한 정보를 두 번째 물리적 블록에 기록합니다.
- 두 번째 기록이 성공적으로 완료된 후에만 output이 완료됩니다.
- (결론 : 두 개의 physical block에 write해서 안정성을 높인다)
- (각 블록의 두 복사본을 가정하여) 다음과 같이 output 작업을 실행:
Recovery and Atomicity
- 데이터베이스 솔루션:
- failure에도 불구하고 atomicity을 보장하기 위해 데이터베이스 자체를 수정하지 않고 안정된 저장소에 수정 사항을 설명하는 정보를 먼저 출력합니다.
- log-based Recovery 메커니즘을 자세히 연구합니다.
- 먼저 주요 개념을 제시합니다.
- 그런 다음 실제 Recovery 알고리즘을 제시합니다.
- 덜 사용되는 대안: 섀도우 복사(Shadow-Copy) 및 섀도우 페이징(Shadow-Paging)
Recovery and Atomicity
- 덜 사용되는 대안: 섀도우 복사(Shadow-Copy) 및 섀도우 페이징(Shadow-Paging)

Log-Based Recovery
- 로그(Log)는 로그 레코드(Log Records)의 시퀀스입니다. 로그 레코드는 데이터베이스에서 업데이트 활동에 대한 정보를 유지합니다.
- 로그는 안정된 저장소에 보관됩니다.
- Transaction Ti가 시작될 때, 로그 레코드를 작성하여 자신을 등록합니다.
- Ti가 write(X)를 실행하기 전에, <Ti, X, V1, V2> 로그 레코드를 작성합니다.
- 여기서 V1은 쓰기 전의 X의 값(Old Value)이고, V2는 X에 쓰여질 값(New Value)입니다.
- Ti가 마지막 명령문을 완료하면 로그 레코드가 작성됩니다. (로그가 디스크에 저장되기 전 까지는 커밋 된게 아니다)
Log Example

Undo and Redo Operations
- Undo and Redo of Transactions
- undo(Ti) — Ti가 업데이트한 모든 데이터 항목의 값을 마지막 로그 레코드부터 뒤로 돌아가면서 원래 값으로 복원합니다.
- 데이터 항목 X의 각 시간이 원래 값 V로 복원되면 <Ti, X, V> 로그 레코드가 작성됩니다.
- Transaction이 중단되면 로그 레코드가 작성됩니다.
- redo(Ti) — Ti가 업데이트한 모든 데이터 항목의 값을 첫 번째 로그 레코드부터 앞으로 진행하면서 새로운 값으로 설정합니다.
- 이 경우 로깅은 수행되지 않습니다.
- undo(Ti) — Ti가 업데이트한 모든 데이터 항목의 값을 마지막 로그 레코드부터 뒤로 돌아가면서 원래 값으로 복원합니다.
Recovering from Failure
- failure 이후 recovering 할 때 로그가 존재한다면 Transaction Ti는 undone 되야 한다
- <Ti start> record를 포함하는 경우
- <Ti commit> 또는 <Ti abort> 가 포함되어 있지 않는 경우
- 로그가 있는 경우 Ti를 다시 수행해야 한다(redone)
- <Ti start> record를 포함하는 경우
- <Ti commit> 또는 <Ti abort> 가 포함되어 있는 경우
Recovery Example

각 상황에 따른 Recovery 조치는 다음과 같습니다:
(a) undo(T₀): B는 2000으로 Recovery되고 A는 1000으로 Recovery됩니다. 로그 레코드 <T₀, B, 2000>, <T₀, A, 1000>, <T₀, abort>이 기록됩니다.
(b) redo(T₀)와 undo(T₁): A와 B는 950과 2050으로 설정되고, C는 700으로 Recovery됩니다. 로그 레코드 <T₁, C, 700>, <T₁, abort>가 기록됩니다.
(c) redo(T₀)와 redo(T₁): A와 B는 각각 950과 2050으로 설정됩니다. 그 후 C는 600으로 설정됩니다.
Checkpoints (체크포인트)
- 로그에 기록된 모든 트랜잭션을 다시 수행하거나 취소하는 것은 매우 느릴 수 있습니다.
- 시스템이 오랫동안 실행된 경우 전체 로그를 처리하는 것은 시간이 많이 걸립니다.
- 이미 데이터베이스에 업데이트를 출력한 트랜잭션을 불필요하게 다시 수행할 수 있습니다.
- 주기적으로 체크포인트를 수행하여 Recovery 절차를 간소화합니다.
- 현재 메인 메모리에 있는 모든 로그 레코드를 안정 저장소에 출력합니다.
- 모든 수정된 버퍼 블록을 디스크에 출력합니다.
<checkpoint L>로그 레코드를 안정 저장소에 기록합니다. 여기서 L은 체크포인트 시점에 활성 상태인 모든 트랜잭션의 목록입니다.- 체크포인트를 수행하는 동안 모든 업데이트가 중지됩니다.
Example of Checkpoints
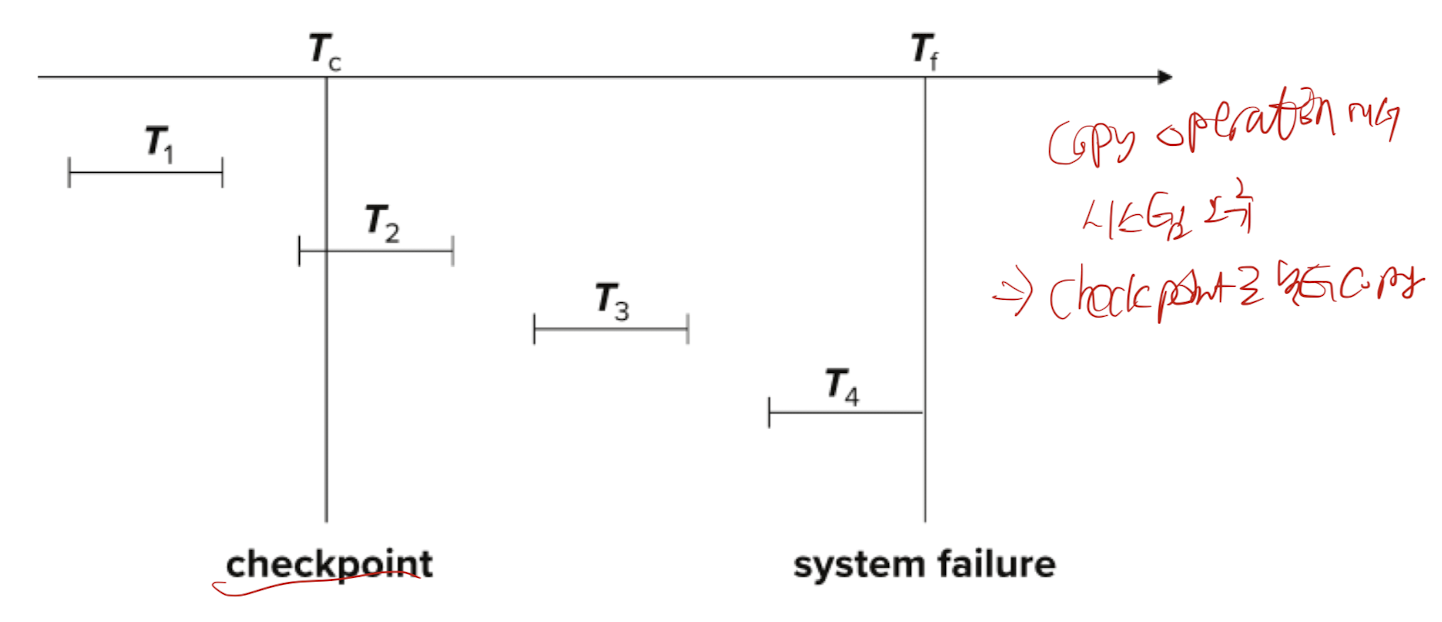

1. T1은 체크포인트 이전에 이미 완료되어 디스크에 변경사항이 반영되었으므로 무시 (복구 대상이 아님)
2. T2, T5는 체크포인트 시점에 진행중이 였으므로 복구 대상에 포함되어야 함
3. T2에 대한 완료 로그가 있으므로, redo를 수행한다. 체크 포인트 이전 부분은 이미 디스크에 반영되었으므로 체크포인트 이후작업만 다시 수행
4. T3가 시작되었다는 로그를 확인하고 복구대상에 포함한다. T3의 완료로그를 읽으면 redo 한다
5. T4의 시작로그를 읽고 복구대상에 포함한다.
6. 고장 시점에 다다르면 복구 대상에 남아있는 transaction을 undo한다. 이 때 T5는 undo를 위해 체크포인트 이전 시점의 로그까지 사용한다.
'DataBase > LegacyPosts' 카테고리의 다른 글
| [DataBase] 10. Normalization(정규화) (0) | 2024.06.26 |
|---|---|
| [DataBase] 09. BigData and Distributed DataBase (0) | 2024.06.26 |
| [DataBase] 07. Data Storage Structure (0) | 2024.06.25 |
| [DataBase] 06. Physical Storage System (0) | 2024.06.25 |
| [DataBase] 05. E-R Model (0) | 2024.06.25 |