File Organization
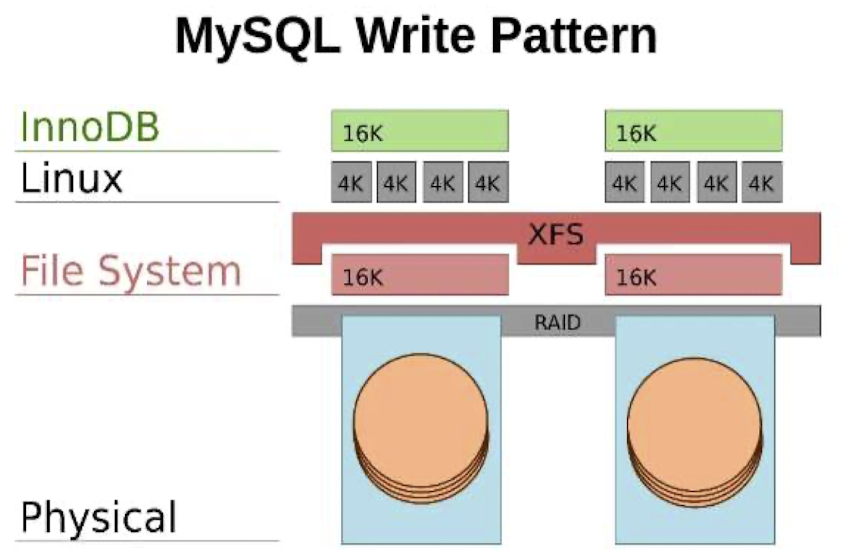
- From MySQL to InnoDB
- Function calls
- From InnoDB to Linux
- System call
- From Linux to File System
- Ext4_file_Write_iter
- From File System to HDD
- SATA_commands

- 데이터베이스는 파일의 모음으로 저장됨
- 각 파일은 records의 sequence
- 각 파일은 하나 이상의 페이지로 구성됨
- 각 페이지는 하나 이상의 레코드를 포함함
- 레코드는 필드의 시퀀스
- 각 파일은 records의 sequence
- 하나의 접근 방법
- 레코드 크기가 고정되어 있다고 가정
- 각 파일은 하나의 특정 유형의 레코드만 포함
- 서로 다른 Relation을 위해 서로 다른 파일 사용
- 레코드는 디스크 블록보다 작다고 가정한다.
Fixed-Length Records
- 간단한 접근 방법
- 각 레코드 i를 바이트 n * i부터 저장, 여기서 n은 각 레코드의 크기
- 레코드 접근은 간단하지만 레코드가 블록을 넘을 수 있음
- 수정: 레코드가 블록 경계를 넘지 않도록 함
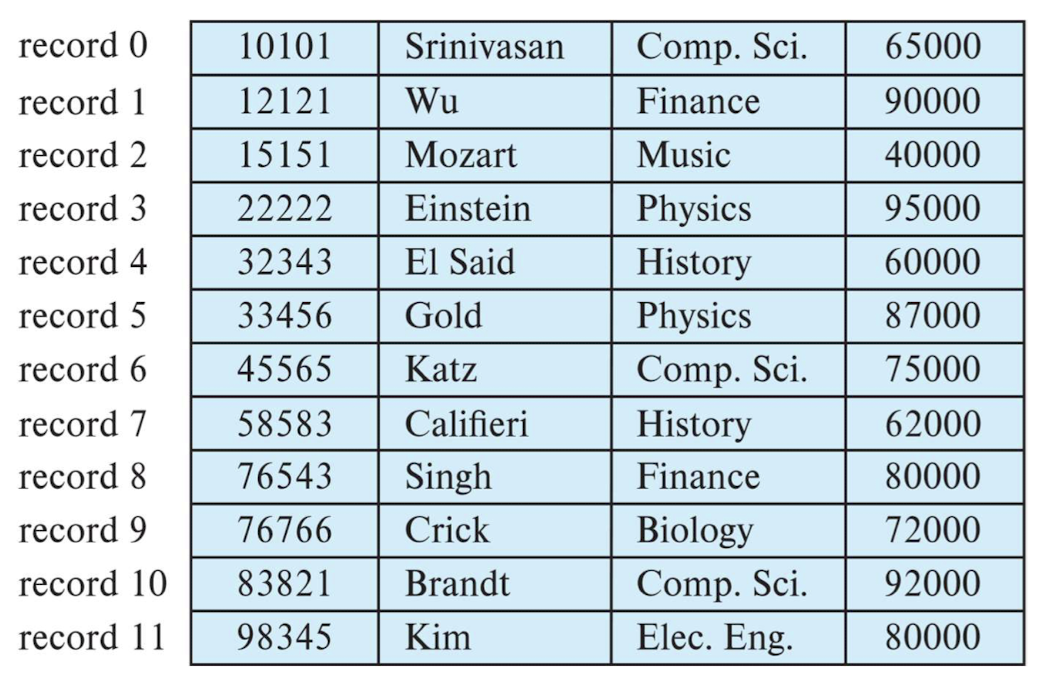
- 레코드 i의 삭제:
- 대안 3가지:
- 1. 레코드 i + 1, ..., n을 i, ..., n - 1로 이동
- 2. 레코드 n을 i로 이동
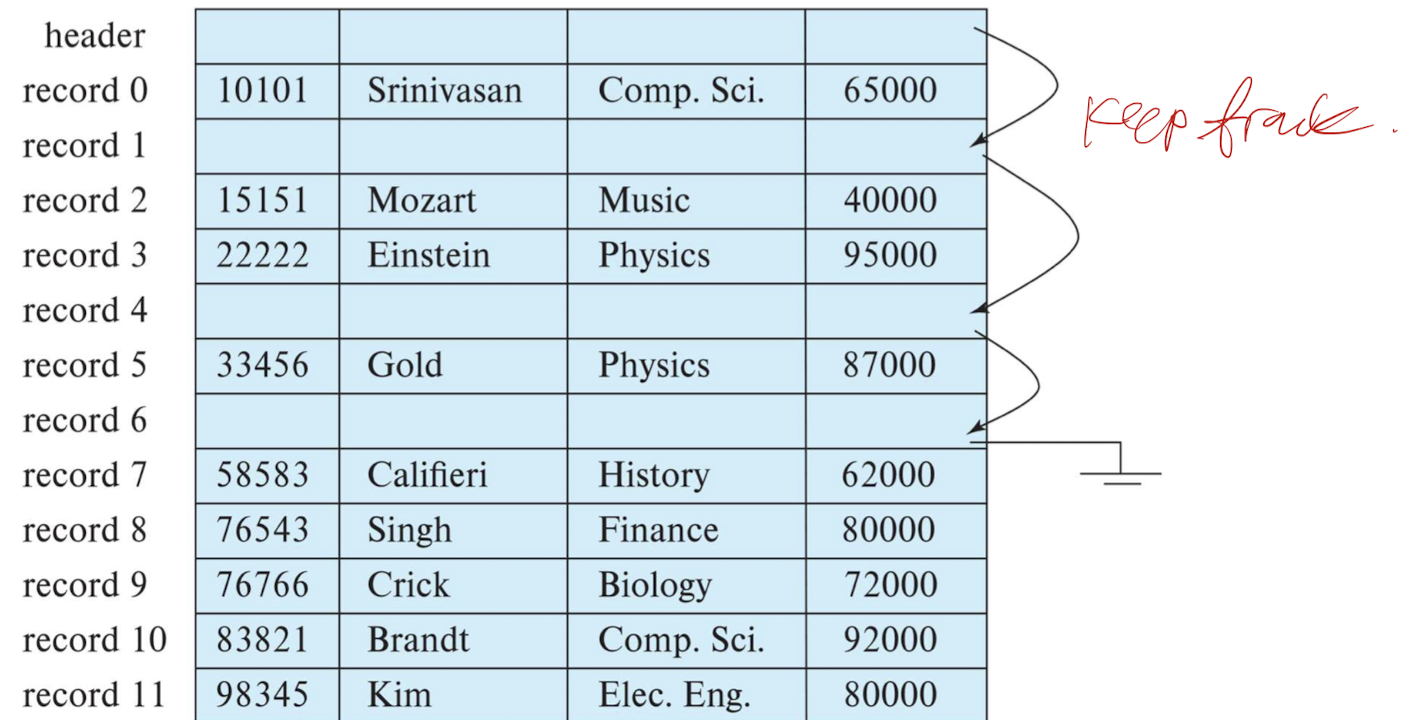
- 3. 레코드를 이동하지 않고 모든 자유 레코드를 자유 목록에 연결
- 대안 3가지:
- 예: 레코드 3 삭제됨 (1. 레코드 i + 1, ..., n을 i, ..., n - 1로 이동하는 방법)
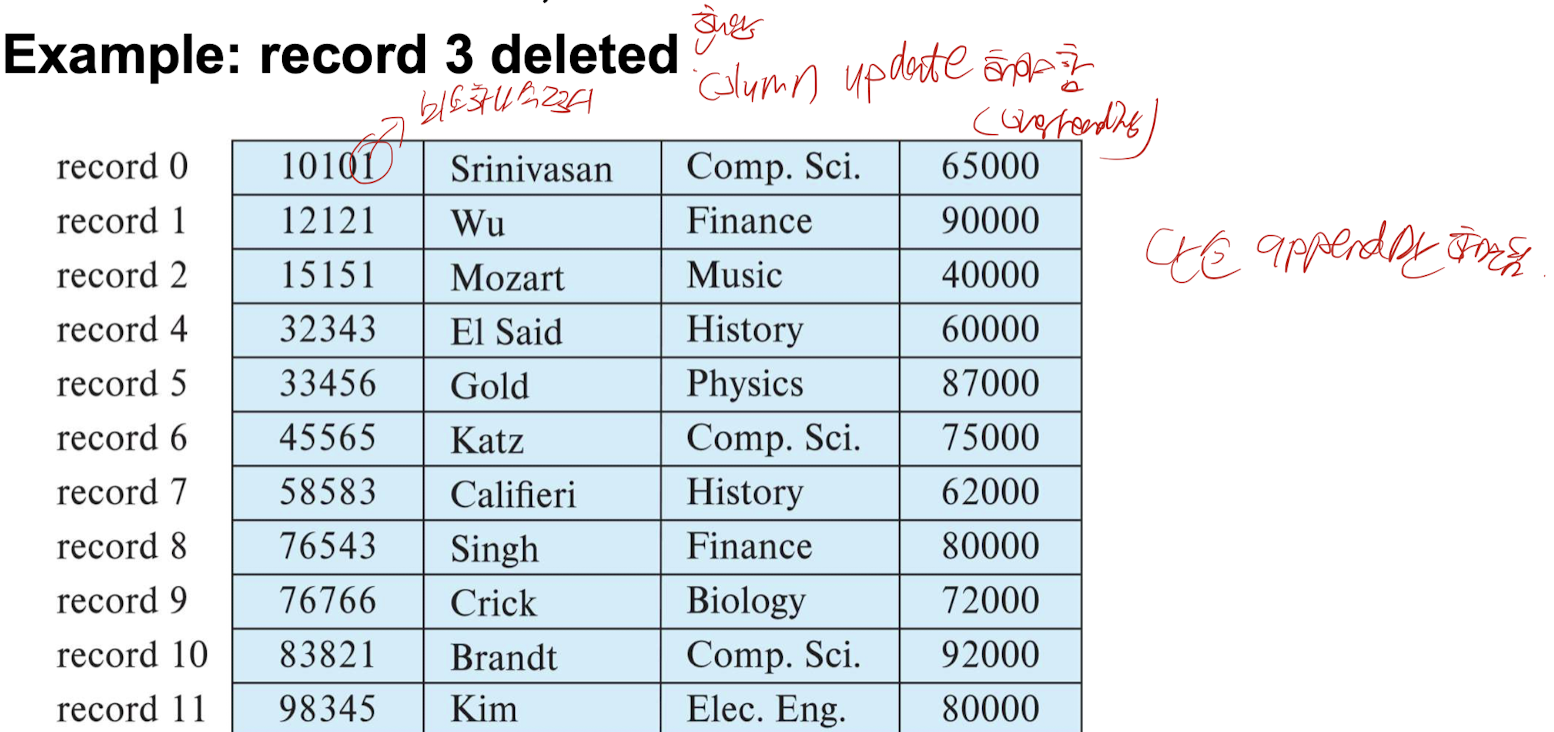
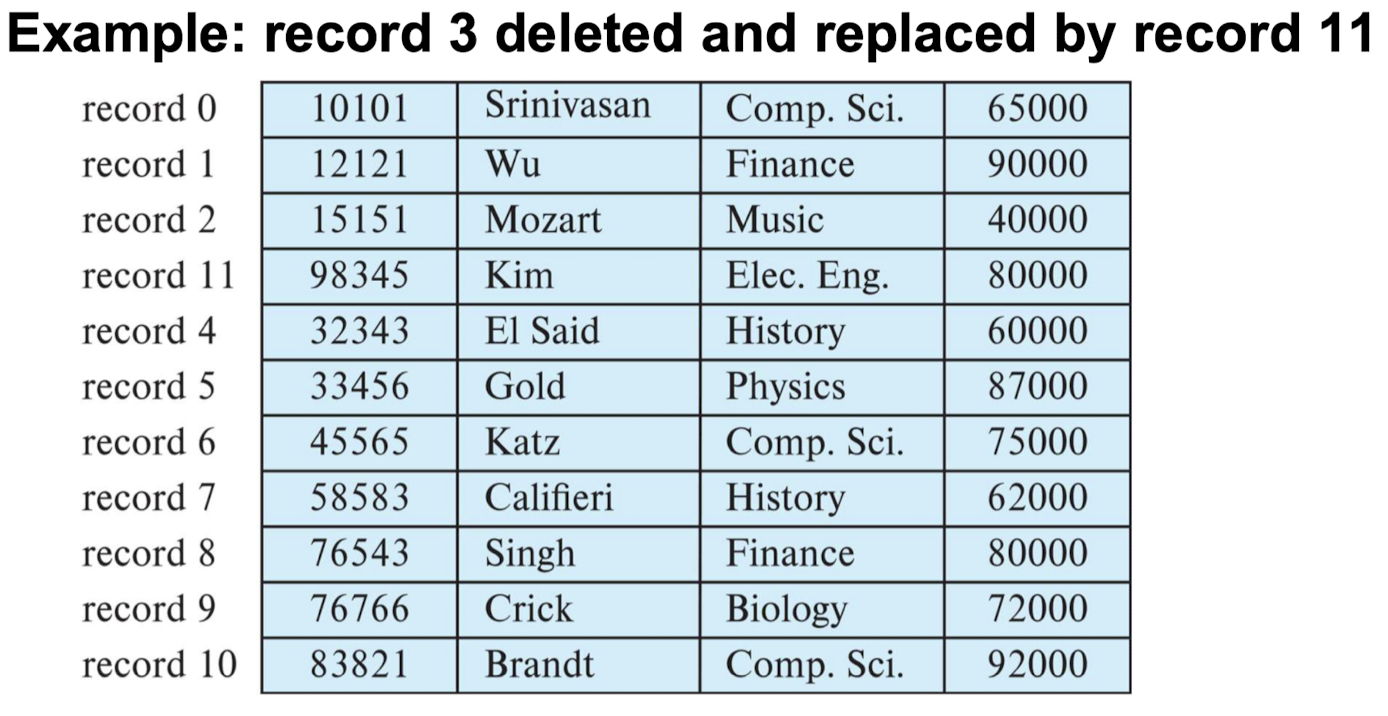
- 예: 레코드 3 삭제되고 레코드 11로 대체됨(2. 레코드 n을 i로 이동하는 방법)
- 3. 레코드를 이동하지 않고 모든 자유 레코드를 자유 목록에 연결하는 방법
Variable-Length Records
(사실 Fixed-Length인 경우는 매우 드물다)
- Variable-length 레코드는 여러 방식으로 데이터베이스 시스템에서 발생:
- 파일에서 여러 레코드 유형 저장
- 하나 이상의 필드 (예: varchar)에 대해 가변 길이를 허용하는 레코드 유형
- 예
- Attribute는 순서대로 저장됨
- 가변 길이 Attribute는 고정 크기 (offset, length)로 표현되며, 실제 데이터는 모든 고정 길이 Attribute 후에 저장됨
- Null 값은 null-value bitmap으로 표현됨

Variable-Length Records: Slotted Page Structure
- Slotted page
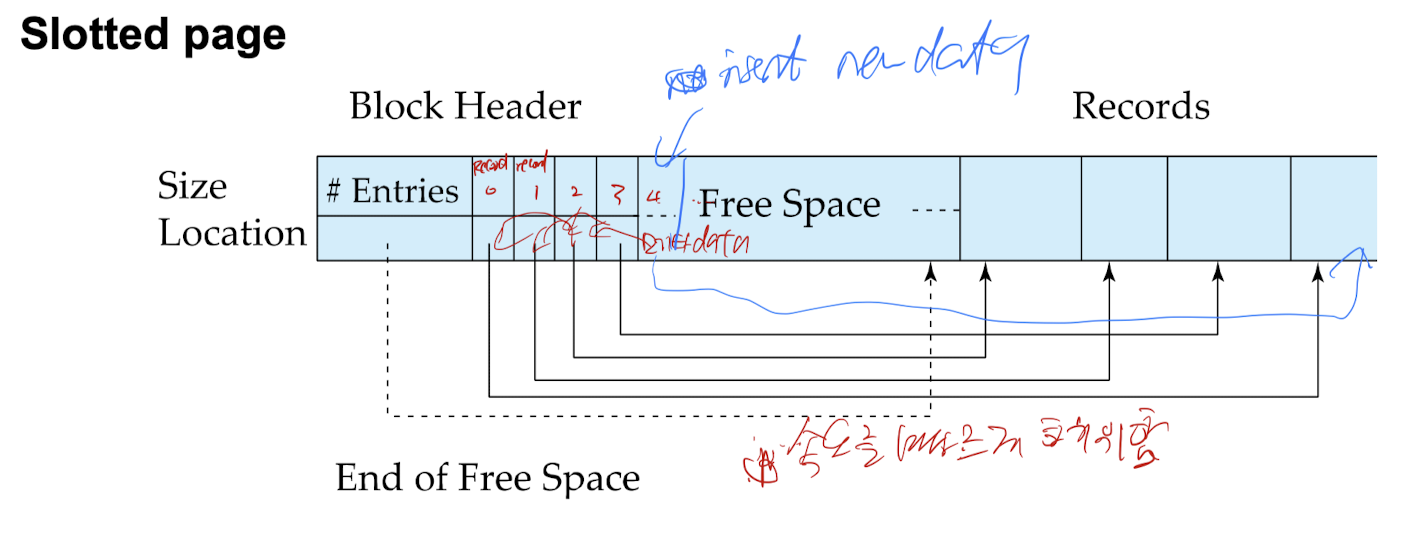
- 슬롯 페이지 헤더에는 다음이 포함됨:
- 레코드 엔트리 수
- 블록 내 빈 공간의 끝
- 각 레코드의 위치와 크기
- 레코드는 페이지 내에서 이동할 수 있으며, 이를 통해 레코드 사이에 빈 공간이 없도록 유지; 헤더 내의 엔트리는 업데이트되어야 함
Organization of Records in Files
- Heap
- 가장 간단하고 기본적인 조직 형태
- heap file organization에서는 레코드가 파일의 끝에 삽입됨
- 레코드가 삽입될 때, 레코드의 정렬 및 정리가 필요하지 않음
- 레코드는 파일 내의 공간이 있는 곳 어디에나 배치될 수 있음
- Sequential
- 레코드를 검색 키의 값에 따라 순차적으로 저장
- In a multitable clustering file organization
- 여러 다른 관계의 레코드가 동일한 파일에 저장될 수 있음
- Motivation: I/O를 최소화하기 위해 관련된 레코드를 동일한 블록에 저장
- 여러 다른 관계의 레코드가 동일한 파일에 저장될 수 있음
- B+-tree file organization
- 삽입/삭제가 있어도 정렬된 저장 공간
- Hashing
- 검색 키에 대해 계산된 해시 함수를 사용; 결과는 파일의 어느 블록에 레코드를 배치해야 하는지 지정함
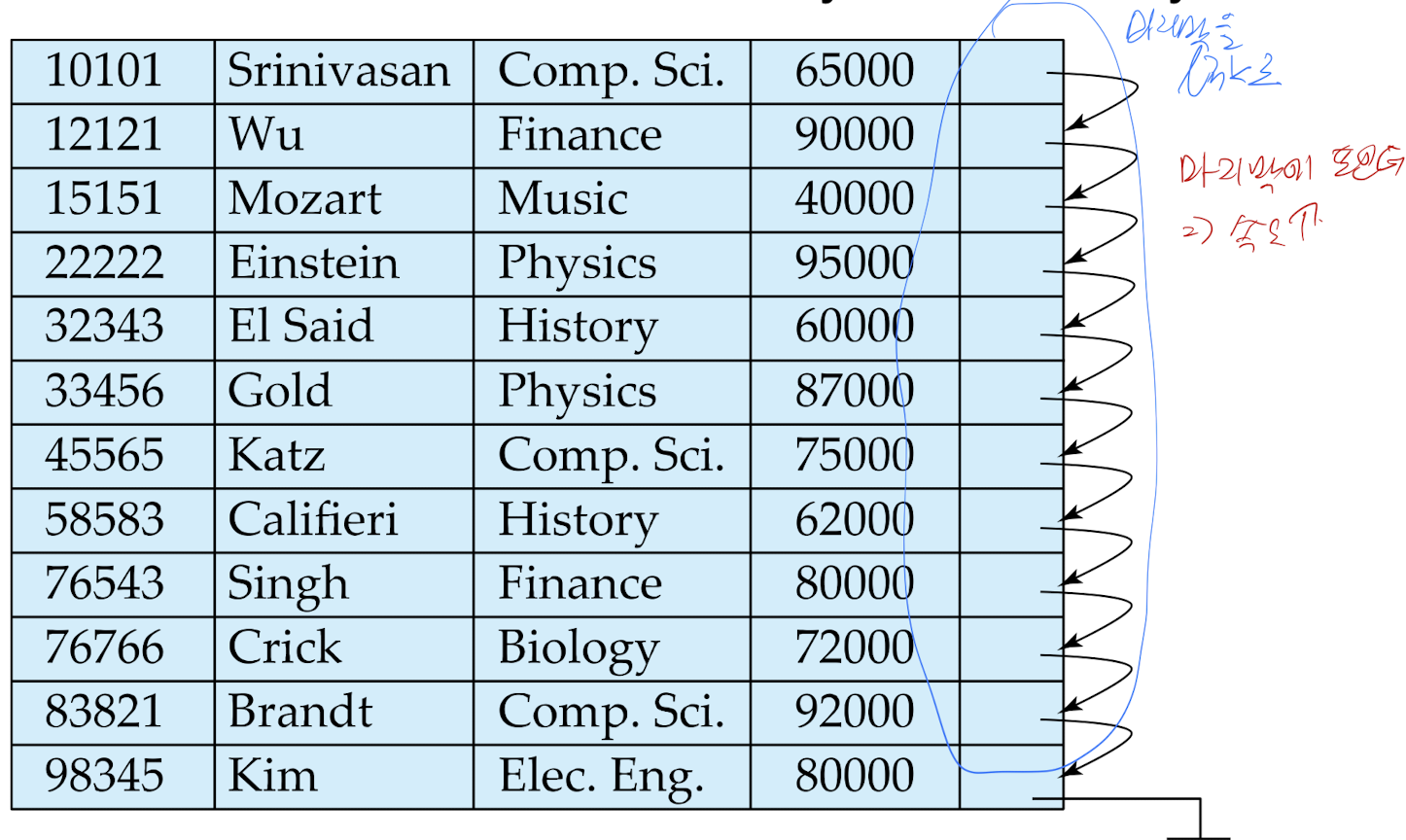
Sequential File Organization
- 전체 파일의 순차적 처리를 필요로 하는 응용 프로그램에 적합
- 파일의 레코드는 Search-key로 정렬됨
- 삭제
- 포인터 체인을 사용
- 삽입
- 레코드를 삽입할 위치를 찾기
- 여유 공간이 있으면, 그 공간에 삽입
- 여유 공간이 없으면, overflow block에 레코드를 삽입
- 어떤 경우든, 포인터 체인을 업데이트해야 함
- 레코드를 삽입할 위치를 찾기
- (이 방법으로 삽입과 삭제를 하면 포인터가 너무 복잡해지는 단점이 존재한다)
- (급격한 변화가 없는 주식 시장에서 사용하는 방식이다)
- 파일을 정기적으로 재조직하여 순차적 순서를 복원해야 함
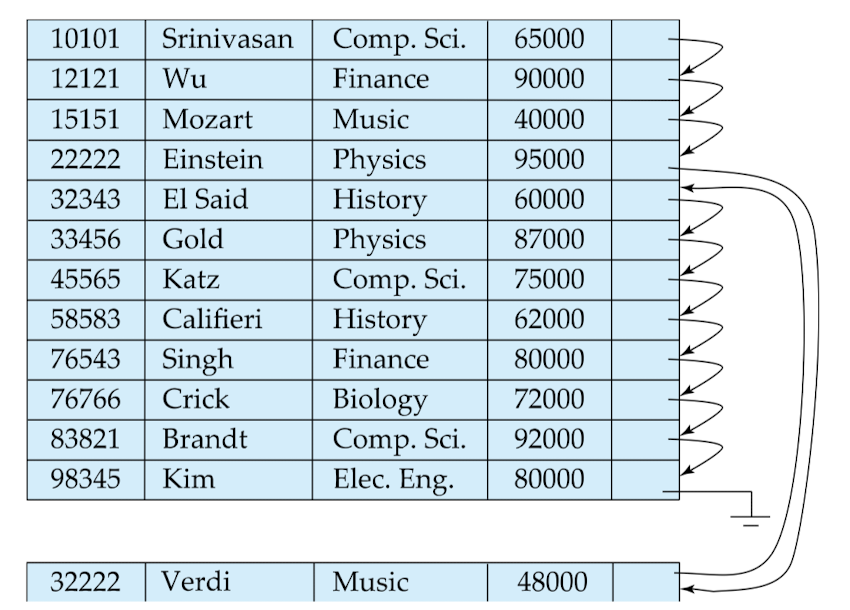
- (bottom에 데이터가 계속 추가되고, keep track 한다)
Multitable Clustering File Organization
- multitable clustering file organization을 사용하여 하나의 파일에 여러 relation을 저장
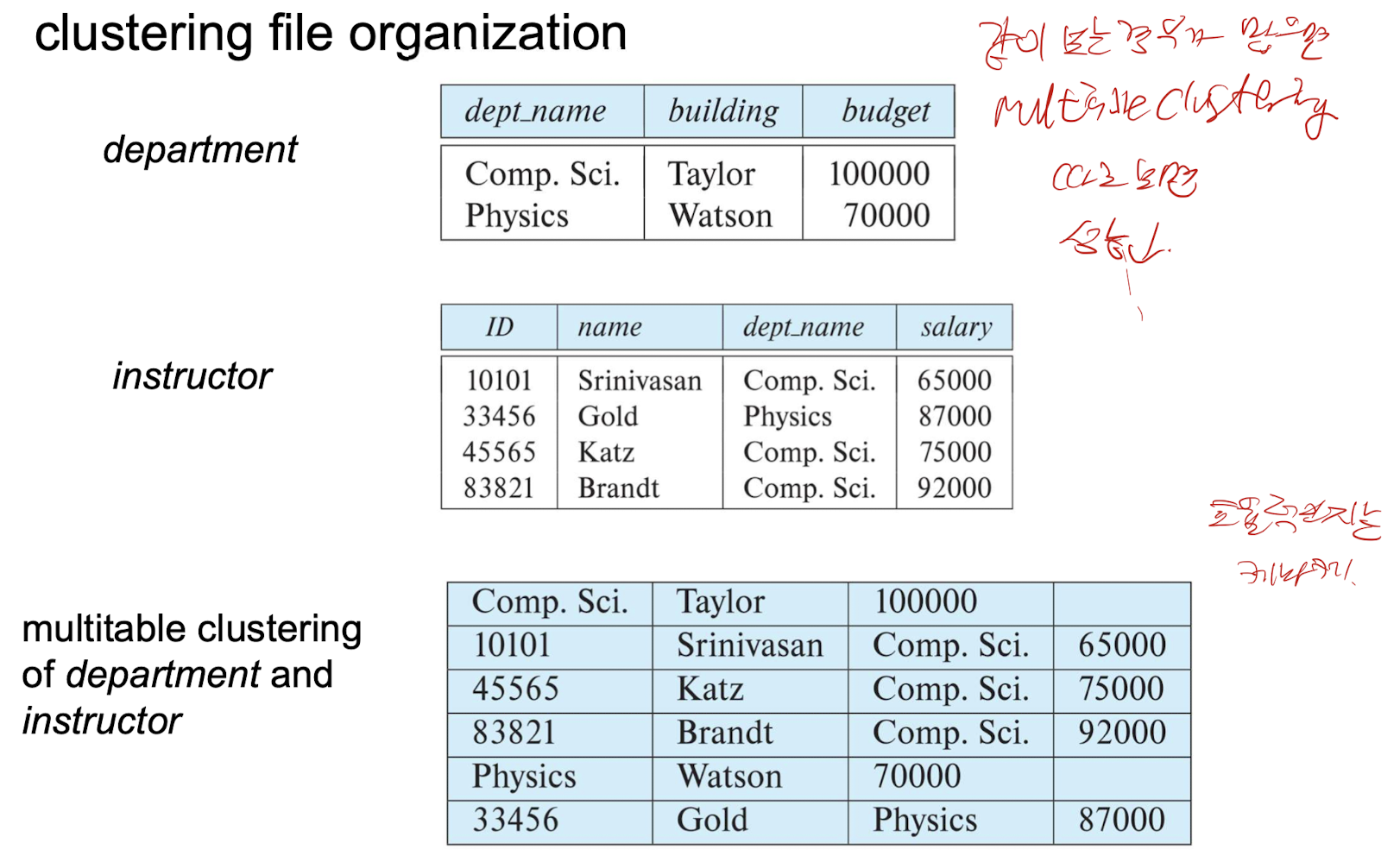
- 장점
- 조인을 포함한 쿼리에 적합
- 단일 department와 관련된 instructor를 포함한 쿼리에 적합
- 단점
- 단일 department만 포함하는 쿼리에 적합하지 않음
- 가변 크기의 레코드를 생성
- 특정 relation의 레코드를 연결하기 위해 포인터 체인을 추가할 수 있음
B+ Tree
(MySQL, MariaDB 등에서 기본으로 사용하는 방식. 평균적인 속도가 빠름)
- B+ Tree는 균형 이진 검색 트리(balanced binary search tree)임
- 예시
- 아래의 B+ 트리 구조에서 55를 검색해야 한다고 가정
- 먼저 중간 노드를 검색하여 55 레코드를 포함할 수 있는 리프 노드로 이동
- 중간 노드에서 50과 75 노드 사이의 브랜치를 찾음
- 마지막으로 리프 노드로 리디렉션됨
- 여기서 DBMS는 55를 찾기 위해 순차 검색을 수행
- 예시
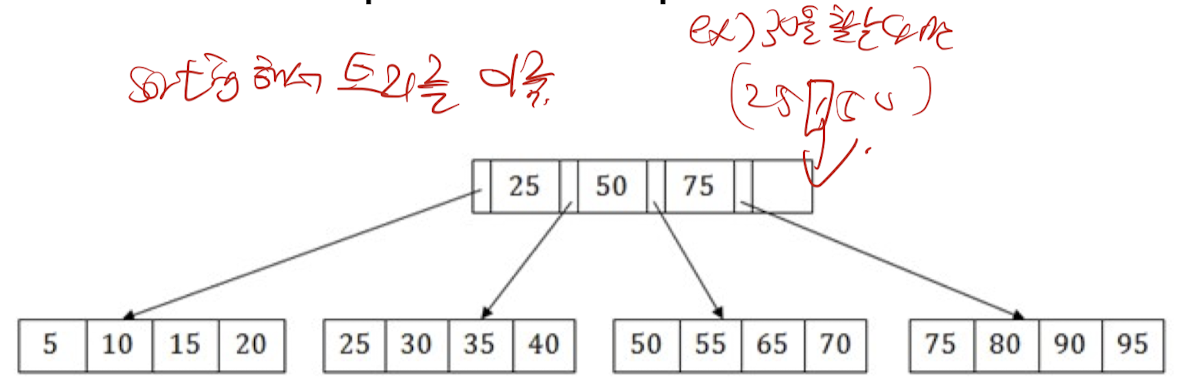
Data Dictionary Storage
- Data Dictionary (또는 시스템 카탈로그)는 메타데이터를 저장; 즉, 데이터에 대한 데이터를 저장
- 메타데이터는 관계에 대한 정보를 포함
- relation의 이름
- 각 relation의 attribute 이름, type 및 length
- 뷰의 이름과 정의
- 무결성 제약 조건(Integrity constraints)
- 사용자 및 계정 정보 (비밀번호 포함)
- 통계 데이터
- 물리적 파일 조직 정보
- relation이 저장되는 방식 (순차/해시/...)
- relation의 물리적 위치
- 인덱스에 대한 정보
- 메타데이터는 관계에 대한 정보를 포함
Storage Access
- 블록은 storage allocation 및 data transfer의 단위
- 데이터베이스 시스템은 디스크와 메모리 간의 블록 전송 수를 최소화하려고 함
- 가능한 많은 블록을 메모리에 유지하여 디스크 액세스 수를 줄일 수 있음
- Buffer(버퍼)
- 디스크 블록의 복사본을 저장하기 위해 사용 가능한 main memory의 일부
- Buffer Manager
- 메인 메모리에서 버퍼 공간을 할당하는 하위 시스템

Buffer Manager
- Buffer Manager의 작동
- 프로그램은 디스크에서 블록이 필요할 때 Buffer Manager를 호출
- 블록이 이미 버퍼에 있는 경우, Buffer Manager는 메인 메모리에서 블록의 주소를 반환
- 블록이 버퍼에 없는 경우, Buffer Manager는
- 블록을 위한 버퍼 공간을 할당
- 여유 공간이 있는 경우
- 버퍼에 새 블록 할당
- 여유 공간이 없는 경우
- 새 블록을 위해 공간을 만들기 위해 다른 블록을 대체 (버림)
- 대체된 블록은 디스크에서 마지막으로 읽거나 수정된 경우에만 다시 씀
- 여유 공간이 있는 경우
- 디스크에서 버퍼로 블록을 읽고, 요청자에게 메인 메모리의 블록 주소를 반환
- 블록을 위한 버퍼 공간을 할당
- 프로그램은 디스크에서 블록이 필요할 때 Buffer Manager를 호출
- Buffer 교체 전략
- Pinned block
- 디스크에 다시 쓰여지지 않는 메모리 블록
- Shared and exclusive locks buffer
- 페이지 내용을 읽는 동안 동시에 작동을 방지하고, 한 번에 하나의 이동/재구성을 보장하기 위해 필요
- Reader는 shared lock을 얻고, 블록을 업데이트하려면 exclusive lock을 요구
- 잠금 규칙:
- 한 번에 한 프로세스만 exclusive lock을 얻을 수 있음
- Shared lock은 exclusive lock과 동시에 존재할 수 없음
- 여러 프로세스가 동시에 shared lock을 가질 수 있음
- Pinned block
Buffer-Replacement Policies
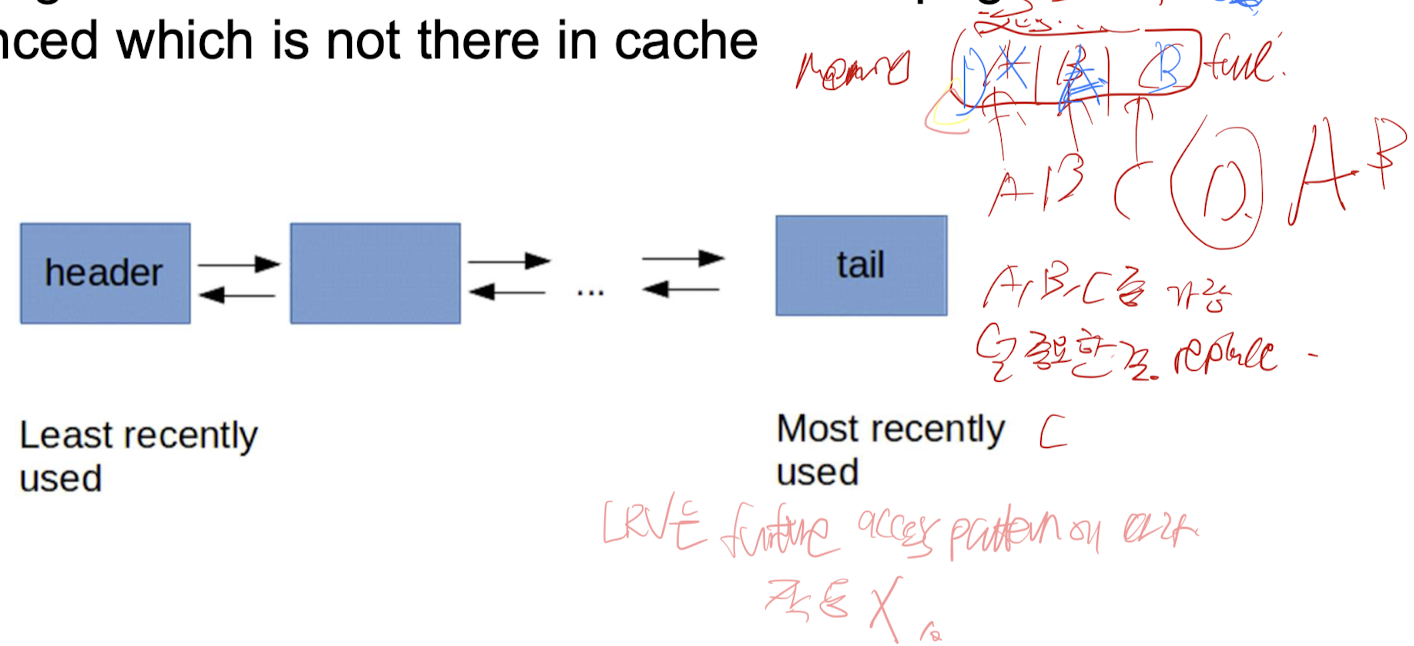
- 대부분의 OS는 가장 최근에 사용되지 않은 블록을 대체 (LRU 전략)
- 이전 블록 참조 패턴을 미래 참조의 예측자로 사용
- LRU 캐싱 방식은 캐시가 가득 차고 캐시에 없는 새 페이지가 참조될 때 가장 최근에 사용되지 않은 페이지를 제거하는 것
- 자세한 내용은 운영체제 글에서 다뤘다
Column-Oriented Storage
- 각 relation의 각 column을 별도로 저장
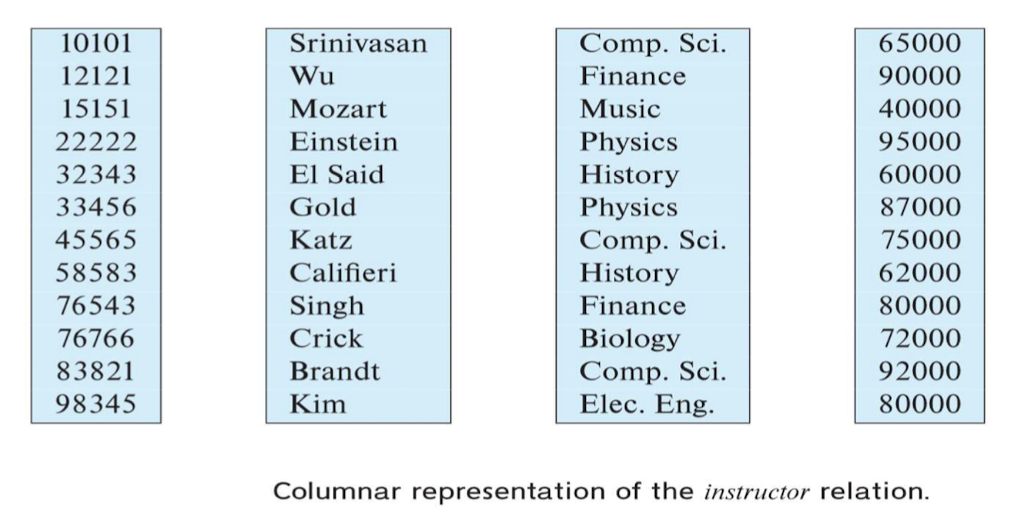
- Row storage vs. Columnar storage
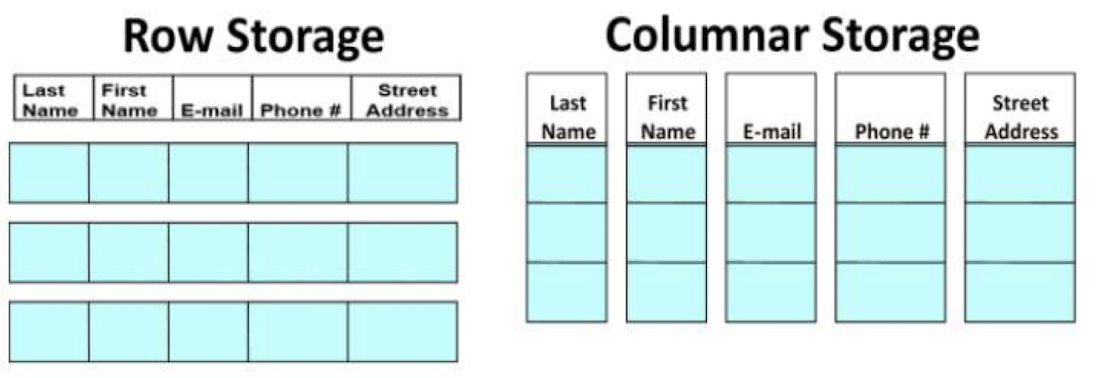
Columnar Representation(컬럼 기반 표현)
- 장점:
- 일부 열만 접근할 경우 I/O 감소
- 단점:
- 컬럼(열) 기반 표현에서 레코드 재구성 비용
- 레코드 삭제 및 업데이트 비용
- 전통적인 행 기반 표현은 트랜잭션 처리를 위해 선호됨
- 일부 데이터베이스는 두 가지 표현 방식을 모두 지원
- hybrid row/column stores라고 불림
'DataBase > LegacyPosts' 카테고리의 다른 글
| [DataBase] 09. BigData and Distributed DataBase (0) | 2024.06.26 |
|---|---|
| [DataBase] 08. Transaction Recovery (0) | 2024.06.26 |
| [DataBase] 06. Physical Storage System (0) | 2024.06.25 |
| [DataBase] 05. E-R Model (0) | 2024.06.25 |
| [DataBase] 04. Intermediate SQL (0) | 2024.06.15 |