10. OOP()
#PLT
객체 지향 패러다임(Object-Oriented Paradigm)
프로그래밍 언어 이론(Programming Language Theory)
객체 지향 프로그래밍(OOP)과 데이터 추상화(Data Abstraction)
데이터 추상화(Data Abstraction)
- 물리적 기계는 bit strings이라는 한 가지 타입만 처리합니다.
- High-level Language에서는 다양한 값을 “wrapping하여 제공합니다.
- 타입(Type): 값 + 연산
- Data Abstraction: 값들이 하나로 결합되어 새로운, 더 추상적인 타입을 형성하고 적절한 연산을 가질 수 있습니다.
- 이러한 새로운 타입을 통해 실제 세계의 복잡한 객체를 표현할 수 있습니다.
장점
- 복잡한 데이터 구조를 더 쉽게 처리할 수 있습니다.
- 세부 사항을 신경 쓸 필요가 없습니다.
- Interface와 Implementation의 분리
- 구현을 알지 못해도 인터페이스를 통해 사용할 수 있습니다.
- Information Hiding: 데이터는 정의된 인터페이스를 통해서만 접근할 수 있습니다.
추상 데이터 타입(Abstract Data Type, ADT)
- ADT의 간단한 형태를 생각해 봅시다.
- type part와 operation part가 있습니다.
- 명세(specification)는 ADT 연산의 의미를 설명합니다.
- 예:
push()는 스택의 맨 위에 요소를 삽입합니다.
- 예:
abstract class Stack {
struct Stack {
int info;
Stack next;
}
// 연산들
Stack create();
Stack push(Stack s, int x);
Stack pop(Stack s);
int top(Stack s);
}
클래스로 ADT를 표현하긴 했지만, ADT는 클래스랑은 상관이 없다.
- 명세를 올바르게 구현하고 인터페이스를 유지하는 한 ADT 사용에 차이가 없습니다.
- definition과 use을 분리합니다.
- 정보(데이터 및 구현)가 숨겨지고 보호됩니다.
표현 독립성(Representation Independence)
- ADT의 단일 명세에 대한 두 개의 올바른 구현은 이 타입을 사용하는 클라이언트에게 동일하게 보입니다.
- type-safe language에서는
- 시그니처(인터페이스)가 같은 다른 ADT로 대체해도 타입 오류가 발생하지 않습니다.
- 필요충분조건이다~
ADT의 한계
- 간단한 Counter 예시를 살펴봅시다.
- 타입 부분은 단순히 카운터가 정수임을 나타냅니다.
- 연산 부분은 카운터의 몇 가지 주요 기능을 구현합니다.
abstract class Counter {
int c;
void reset();
int get();
void increment();
}
- 조금 더 고급화된 카운터가 필요하다고 가정해봅시다.
- 이제 리셋 횟수를 기록하기 위한 추가 필드를 ADT에 추가할 수 있습니다.
- 이제
reset()은 Counter와 다릅니다.
예시:
abstract Counter2 {
type Counter2 =
struct {
int x;
int num_reset;
}
operations:
void reset(Counter2 c) {
c.x = 0;
c.num_reset += 1;
}
int get(Counter2 c) {
return c;
}
void increment(Counter2 c) {
c = c + 1;
}
int get_resets(Counter2 c) {
return c.num_reset;
}
}
- 문제점은 Counter와 Counter2 사이에 아무런 관계가 없다는 것입니다.
- Counter 명세에 변경이 발생하면, 비록 동일한 연산을 포함하고 있다 하더라도, 모든 ADT에 대해 변경을 해야 합니다.
- 예를 들어, get()과 increment() 같은 연산들이 그렇습니다.
1을 늘려주려면 Counter를 쓰고, 2를 늘려주려면 Counter2를 쓰고, ….100을 늘려주려면 Counter100을 써야 되는 상황
Counter에서 상속하기 (Let's Inherit from Counter)
- Counter의 기존 연산을 재사용하여 Counter3를 만들 수 있습니다.
- Counter와 Counter3 모두를 변경해야 하는 경우, 이제는 Counter에서만 수정하면 됩니다.
- Counter에서 사용할 수 있는 모든 연산이 Counter3에서도 사용할 수 있습니다.
- Counter3는 Counter와 호환됩니다.
예시:
abstract Counter3 {
type Counter3 =
struct {
Counter x;
int num_reset;
}
operations:
void reset(Counter3 c) {
reset(c.x);
c.num_reset += 1;
}
int get(Counter3 c) {
return get(c.x);
}
void increment(Counter3 c) {
increment(c.x);
}
int get_resets(Counter3 c) {
return c.num_reset;
}
}
Counter가 바뀌더라도, Counter3는 다른 걸 손대지 않아도 된다. 단순히 Counter를 호출만 하기 때문.
문제 해결? (Problem Solved?)
- Counter 또는 Counter3 객체가 100개 있는 경우를 가정합시다.
- 모든 객체를 reset하고자 할 때, reset(arr[i])를 호출하면 어떻게 될까요?
- 이 연산은 매개변수로 Counter 또는 Counter3를 받지만, reset(Counter) 연산만 실행됩니다.
- 적합한 메서드를 동적으로 선택할 수 없습니다.
Counter arr[100];
...
arr[9] = new Counter();
arr[10] = new Counter3();
...
for(int i=0; i<100; i++){
reset(arr[i]);
}
void reset(Counter c) {
c = 0;
}
void reset(Counter3 c) {
reset(c.x);
c.num_reset += 1;
}
arr의 타입이 Counter이기 때문에 reset(arr[i])를 하면 reset(Counter c)가 호출된다.
ADT의 한계 (Limits of ADT)
- ADT는 캡슐화와 정보 은닉에는 적합하지만, 더 복잡한 설계에는 유연성이 부족합니다.
- 이를 해결하기 위해 객체 지향 패러다임이 요구하는 네 가지 조건이 필요합니다:
- 캡슐화와 정보 은닉
- 상속 (Inheritance)
- 서브타입 호환성 (Subtype Compatibility)
- 동적 메서드 선택 (Dynamic Method Selection)
OOP 핵심 개념 (OOP Key Concepts)
객체 (Object)
- 객체란 데이터와 연산을 캡슐화한 컨테이너입니다.
- ADT의 변수는 그저 데이터만을 나타냅니다.
- ADT에서는 연산을 호출할 때마다 변수를 매개변수로 전달해야 했습니다.
- 예시:
void increment(Counter c)
- 예시:
- ADT에서는 연산을 호출할 때마다 변수를 매개변수로 전달해야 했습니다.
- 객체 내의 데이터 항목을 인스턴스 변수라 하고, 연산을 메서드라 합니다.
메서드 호출 (Method Invocation)
- 객체의 연산을 수행하려면 해당 객체에 메시지를 보내야 합니다.
- 형식:
object.method(params) - (제어권이 메서드한테 있음)
- 형식:
- 이는 객체에 메서드를 호출하도록 지시하는 것입니다.
- 객체 자체가 메서드의 implicit parameter로 간주될 수 있습니다.
클래스 (Class)
- 클래스는 객체 집합을 모델링한 것입니다.
- 클래스가 있는 언어에서는 모든 객체가 클래스에 속해 있습니다.
- 객체는 클래스의 인스턴스로 볼 수 있습니다.
- 또는 객체는 해당 클래스의 instantiation에 의해 동적으로 생성될 수 있다.
- 예시:
Counter c = new Counter(); - c가 Counter의 object를 가리킨다.
- 보통 constructor를 호출해서 instantiation한다. (클래스로 부터 객체를 만드는 과정을 instantiation이라고 한다)
- 예시:
- 또는 객체는 해당 클래스의 instantiation에 의해 동적으로 생성될 수 있다.
클래스와 객체 (Class and Object)

reset, get, inc는 컴파일 될 때 딱 한 번 저장된다.
만약 static으로 선언되었다면 모든 메서드 정보가 컴파일러에게 전달된다.
인스턴스에서는 static 메서드 정의에 대한 포인터를 가지고 있다.
인스턴스 자체는 동적으로 생성된다.
static 함수에서는 동적으로 생성되는 것들을 사용할 수 없다.
- 메서드는 클래스에 단 한 번만 저장됩니다.
- 각 객체(인스턴스)는 각자의 인스턴스 변수를 가집니다.
- 클래스의 메서드에 대한 포인터가 객체에도 저장됩니다.
- 메서드가 자기 자신을 참조하기 위해 this(또는 self)를 사용합니다.
캡슐화 (Encapsulation)
- 보통 두 가지 뷰가 존재합니다: public과 private.
- 숨겨야 하는 정보는 private에 배치됩니다.
- 일반적으로 데이터와 일부 메서드는 private으로, 인터페이스 역할을 하는 메서드는 public으로 설정됩니다.
- Encapsulation는 데이터를 연산과 함께 클래스라는 캡슐로 감싸는 것입니다.
- Information hiding은 이 캡슐 내부의 세부 사항을 숨기는 것으로, 이를 private area에 배치하여 이루어집니다.
서브타입 (Subtypes)
- 서브타입이란 T가 S의 서브타입일 때, S의 인터페이스가 T의 인터페이스의 부분집합임을 의미합니다.
- S에서 사용 가능한 모든 연산이 T에서도 사용 가능해야 합니다.
- T는 S에 있는 필드와 더불어 추가 필드를 가질 수 있습니다.
예시:
class NewCounter extends Counter {
private int num_reset = 0;
public int get_reset() {
return this.num_reset;
}
}

생성자 (Constructors)
- 객체를 생성하려면 두 가지 작업이 필요합니다:
- 메모리 할당 (Allocation of Memory)
- 객체의 데이터를 초기화하는 초기화 작업 (Initialization)
- 후자는 생성자에 의해 수행됩니다.
- 일반적으로 클래스 이름과 동일한 이름을 사용하거나, 다르게 명확하게 지정된 이름을 사용합니다.
예시:
class Counter {
public Counter() {
...
}
}
class Counter:
def __init__(self):
...
(언어별 예시: C++, Java는 클래스 이름을 생성자로 사용하고, Python은 __init__ 메서드를 생성자로 사용합니다.)
생성자 선택 (Constructor Selection)
- 클래스에 여러 생성자가 있을 수 있습니다. 이는 오버로딩(overloading)으로 불립니다.
- 어떤 생성자를 사용할지 결정해야 합니다.
- 예를 들어 C++에서는 복사 생성자(Copy Constructor)가 존재합니다.
- 생성자 체이닝 (Constructor Chaining)
- 상위 클래스가 초기화되는 시점과 방식에 대한 문제
- 언어의 디자인에 따라 다름
- 자바에서는 제일 먼저 상위 클래스의 생성자를 호출한다.
- 어떤 상위 클래스 생성자를 어떤 인자로 호출할지 결정하는 문제
- 어떤 건 파라미터 2개짜리, 어떤건 3개짜리…
- 상위 클래스가 초기화되는 시점과 방식에 대한 문제
상속 (Inheritance)
- 상속이란 기존 객체(또는 클래스)를 재사용하여 새로운 객체(또는 클래스)를 정의하는 것을 말합니다.
- Inheritance과 Subtype
- Inheritance은 possibility of code reuse(Implementation Inheritance)과 관련이 있습니다.
- 부모 클래스의 상속을 받은 자식에서 부모 클래스의 메서드를 사용할 수 있다.
- Subtype은 compatibility(Interface Inheritance)과 관련이 있습니다.
- Inheritance은 possibility of code reuse(Implementation Inheritance)과 관련이 있습니다.
- protected 키워드를 통해 하위 클래스가 상위 클래스의 멤버에 접근할 수 있도록 합니다.
- 단일 상속(Single Inheritance)과 다중 상속(Multiple Inheritance)
- 하나의 상위 클래스만 상속하는 경우 또는 여러 상위 클래스를 상속하는 경우
- 단일 상속 자바
- 다중 상속 C++
- 다중 상속에서는 문제점이 발생할 수 있습니다.
- Name Conflict
- 다이아몬드 문제(Diamond Problem)
다이아몬드 문제 (Diamond Problem)

C++의 경우 어떤 클래스에 속하는 함수(ex. B::f())인지 밝혀줘야 한다. 안 그러면 에러가 발생한다.
- 다중 상속 시, 어떤 f() 메서드를 호출할지 모호해지는 문제가 발생합니다.
- 명시적으로 qualified name을 사용해 호출할 메서드를 지정해야 합니다.
동적 메서드 조회 (Dynamic Method Lookup)
class Counter {
private int x = 0;
public void reset() {
x = 0;
}
public void inc() {
x += 1;
}
public int get() {
return x;
}
}
class NewCounter extends Counter {
private int num_reset = 0;
public void reset() {
x = 0;
num_reset += 1;
}
public int get_reset() {
return this.num_reset;
}
}
Counter arr[100];
...
arr[9] = new Counter();
arr[10] = new NewCounter();
...
for(int i=0; i<100; i++){
arr[i].reset();
}
이전 예시에서는 reset(arr[i]) 이런식으로 전달해줬기 때문에 무조건 Counter의 reset으로 전달되었지만,
지금은 객체의 메서드를 호출함으로써 동적으로 해당 타입에 대한 메서드를 호출해줄 수 있다.
- 이전 카운터 예시를 다시 살펴봅시다.
- Counter와 NewCounter가 클래스에서 정의된 경우
- 카운터들을 reset하고자 할 때 무슨 일이 발생할까요?
class B extends A {
int b = 0;
void g() { b = 2; }
}
class A {
int a = 0;
void f() { g(); }
void g() { a = 1; }
}
B b = new B();
b.f();
- 컴파일러는 어떤 객체가 해당 메서드를 호출할지 결정할 수 없습니다.
- 예를 들어, 클래스 A에서 f 메서드가 g 메서드를 호출할 때,
this.g()로 호출하게 됩니다.- this가 참조하는 객체에 따라 A의 g가 호출될지, B의 g가 호출될지 결정된다.
- 실행 중에 this가 어떤 객체를 가리키는지에 따라 실제로 호출되는 g 메서드가 결정됩니다.
- 이를 late binding 또는 Dynamic binding이라 부릅니다.
메서드 오버라이딩과 쉐도잉 (Method Overriding and Shadowing)
- 메서드 오버라이딩(Method Overriding): 서브타입에서 메서드를 재정의할 수 있습니다.
- 쉐도잉(Shadowing): 서브타입에서 필드도 재정의할 수 있습니다.
- 다만 메서드 오버라이딩과 필드 쉐도잉에는 차이가 있습니다.
- 오버라이딩은 동적(dynamic)으로 이루어지지만, 쉐도잉은 정적(static)입니다.
public class A {
public int num = 5;
public int update() {
return num-1;
}
}
public class B extends A {
public int num = 3;
public int update() {
return num+5;
}
}
B b= new B();
A a = b;
System.out.println(b.num); //3
System.out.println(b.update()); //8
System.out.println(a.num); //5
System.out.println(a.update()); //8





OOP 구현 (OOP Implementations)
객체: 단순 구현 (Objects: Simple Implementation)
class B extends A {
int b;
void f() { ... } // 재정의됨
void h() { ... }
}
class A {
int a;
void f() { ... }
void g() { ... }
}
B obj = new B();
obj.a;
obj.f();
obj.g();
부모클래스들과 본인 클래스의 멤버 변수를 해당 객체가 가지고 있고, 해당 클래스의 메서드 정보가 담겨 있는 곳의 포인터가 존재한다.
obj가 포인터를 따라 B로 간다 -> f가 있으므로 f를 호출하고, g가 없네? -> 부모 클래스로 계속 가면서 g가 있으면 호출한다.
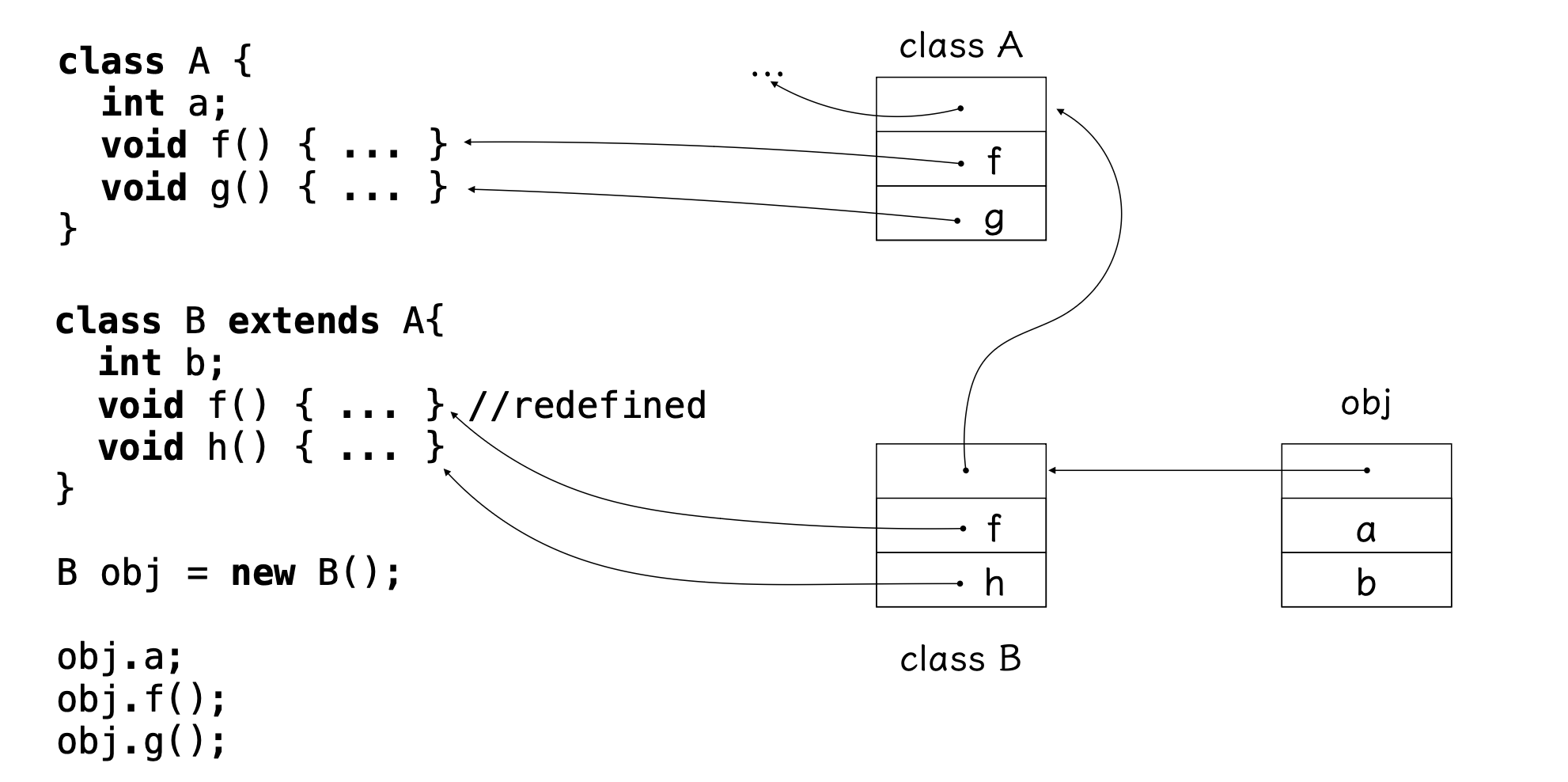
-> 상속을 4~5번 한 클래스의 객체에서 최상위 부모의 메서드를 실행한다면? -> 너무 오래걸린다. (linked list 조회의 O(n)을 생각해보자)
단일 상속 (Single Inheritance)
링크드 리스트의 조회시간을 줄이자 -> 해시 테이블(virtual function table).
필드와 메서드는 컴파일 타임에 결정된다. -> virtual 테이블을 만들어둘 수 있다. 이 virtual table에 클래스의 메서드를 다 놔둔다.
class A {
int a;
char c;
void f() { ... }
void g() { ... }
}
class B extends A {
int a;
int b;
void f() { ... } // 재정의됨
void h() { ... }
}
B pb = new B();
A pa = new A();
A aa = pb;
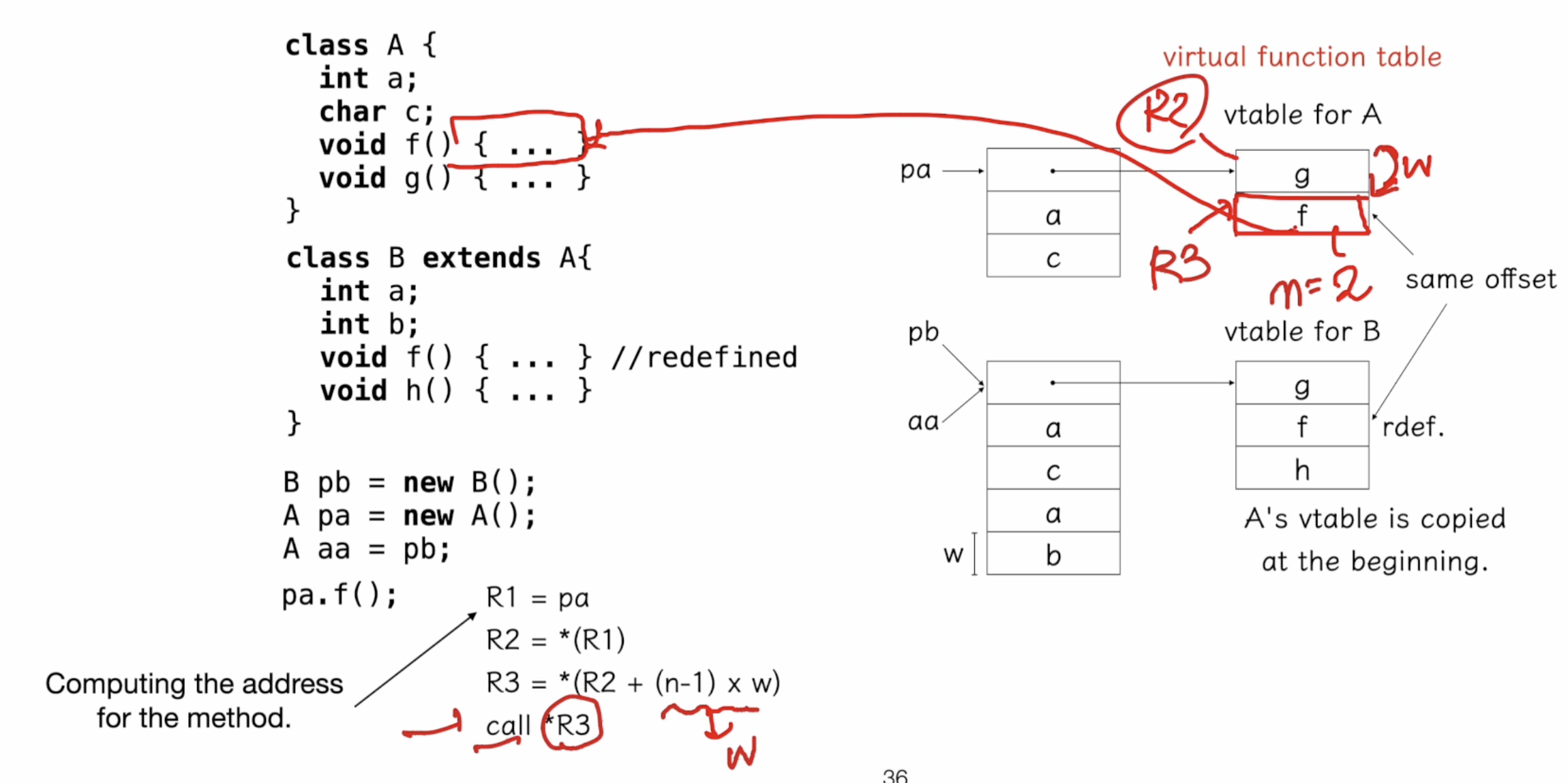
비록 vtable은 컴파일은 정적인 시간에 생성되지만, 어떤 메서드가 호출될 지는 동적으로 결정된다.
다운캐스팅(Downcasting)
다운캐스팅은 상위 클래스에서 하위 클래스로의 캐스팅을 허용합니다.
Object clone() { ... } // 객체 복사 생성
A o = ...;
A a = o.clone(); // Object != A
A a = (A) o.clone(); // OK
다운 캐스팅은 implicit하게 할 수 없다. explicit하게 해줘야 한다.(explicit conversion)
깨지기 쉬운 기본 클래스 문제 (Fragile Base Class Issue)
- 객체 지향 시스템에서 많은 클래스가 존재하며, 일부 클래스는 여러 하위 클래스에 의해 상속되는 일반 클래스입니다.
- 예: Java의 Object 클래스.
- 클래스 계층 구조의 상위에 있는 클래스를 수정할 경우, 그 아래 모든 하위 클래스에 큰 영향을 미칩니다.
- 자식에서 부모 필드를 모두 가지고 있는데, 부모가 바뀌면 영향이 크다.
class A {
int a;
void f() { ... }
}
class B extends A {
int y;
void g() { return y+f(); }
}
// class A가 수정됨
// 메서드 h 추가
class A {
int x;
void h() { return x; }
int f() { ... }
}
컴파일 할 때 vtable이 fixed되는데, h가 추가되는 바람에 A로 부터 상속받은 모든 클래스가 recompile되야 한다.
- 단일 상속 구현에서는 상위 클래스 A가 변경될 경우, f() 메서드를 호출하는 오프셋이 바뀌어 클래스 B에 문제가 발생합니다.
- 이를 해결하려면 가상 함수 테이블의 메서드 오프셋을 동적으로 계산해야 합니다.
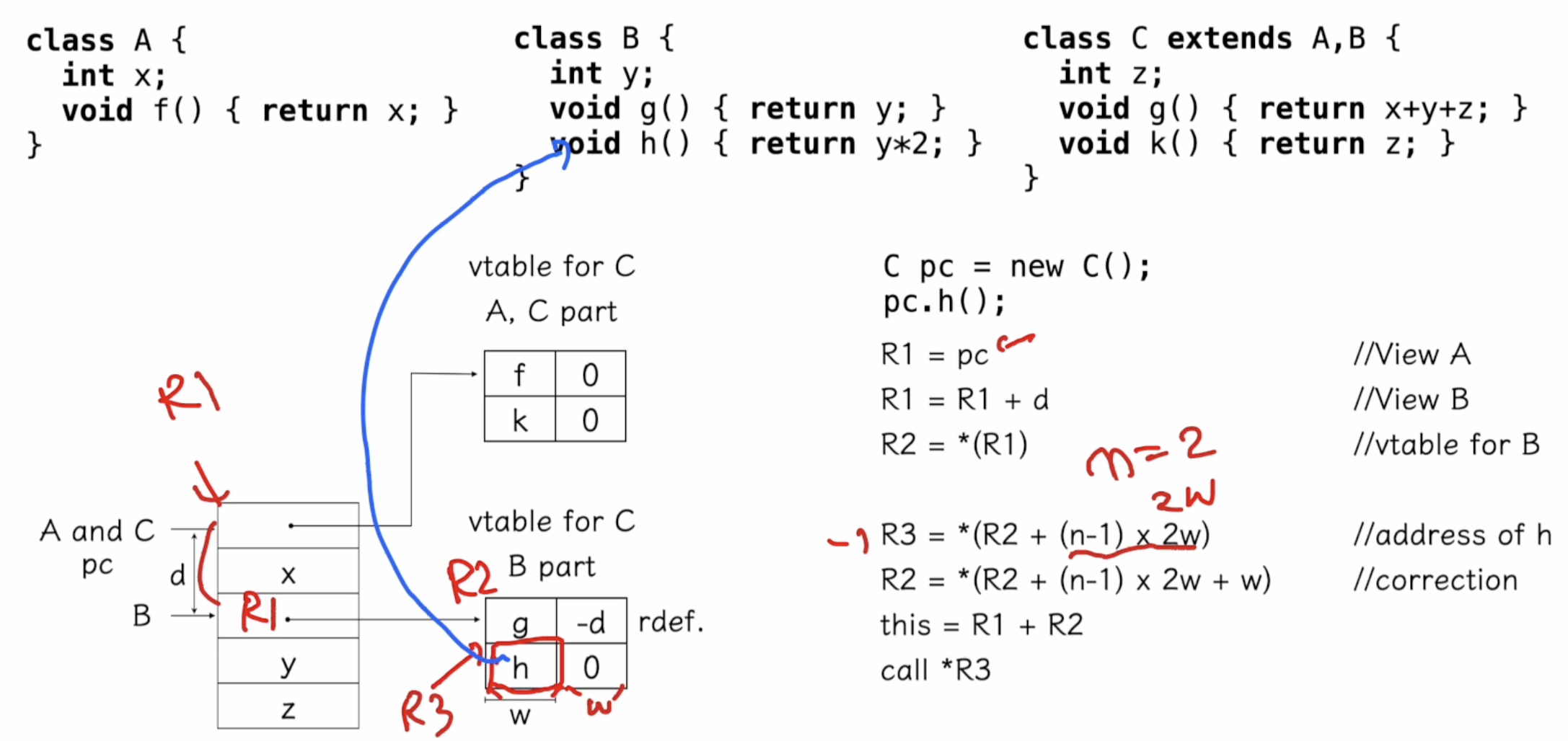
n: 메서드가 몇 번째 인지. 여기서는 n = 2라 n - 1 = 1
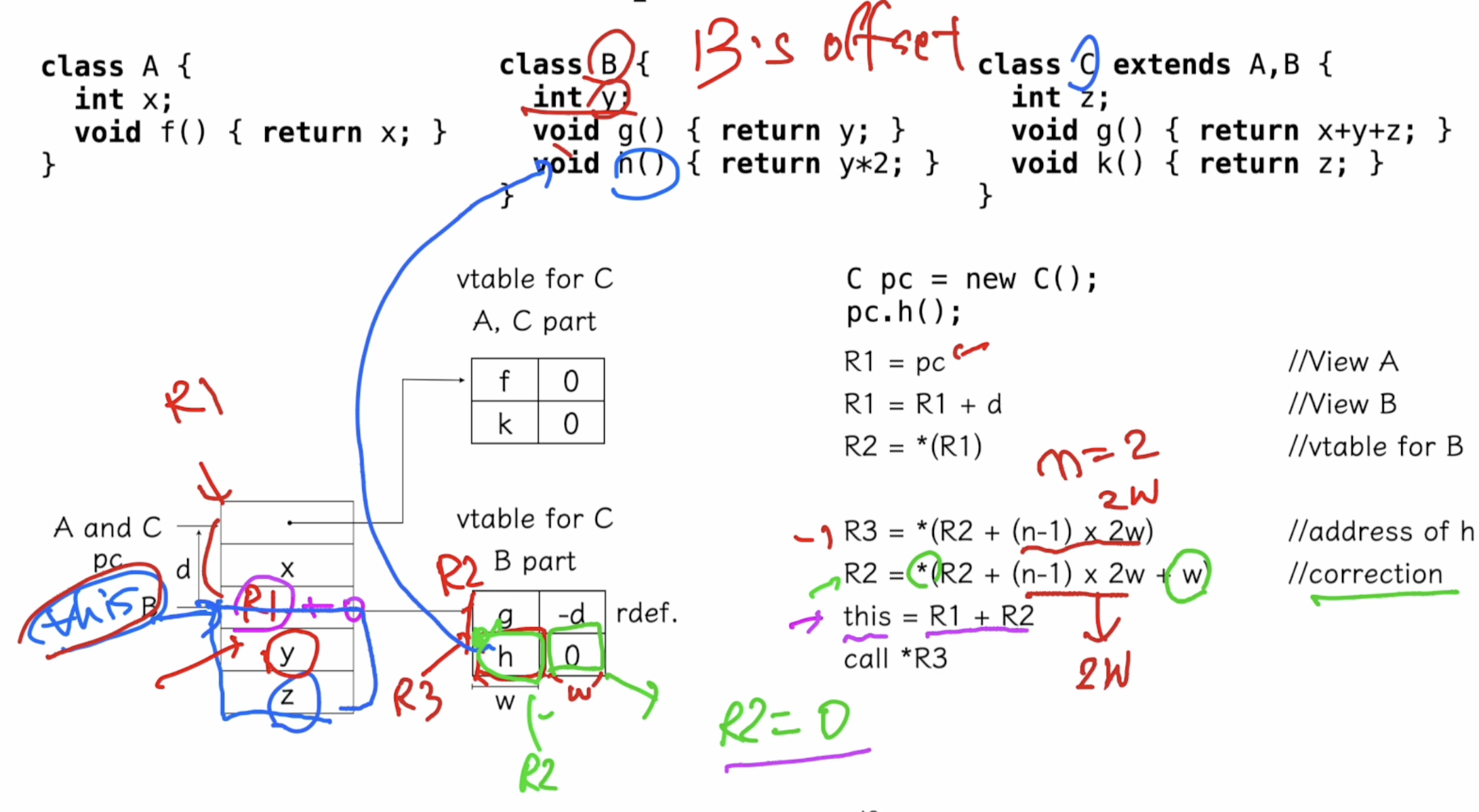
R2: derefence(역참조)를 위해 계산되며, R2의 값이 0이 된다.
R2가 0이되므로 this = R1 + R2 = R1이 된다.
이제 B에서 y의 값을 사용하기 위해선 this 포인터에서 얼만큼 떨어져있는지를 이용해서 사용할 수 있따.
B는 C이전에 선언된 부분이므로, B의 메서드에서는 z 값을 사용할 수 없다. 단순히 y 필드 하나만 있으므로 y값에 못쓴다. y 값을 사용하기 위해서는 B의 offset을 이용하면 된다. y는 B의 첫 번째 멤버변수 임을 알기 때문이다.
설명:
- 다중 상속에서는 하나 이상의 상위 클래스를 상속할 수 있습니다.
- 각 상위 클래스의 가상 함수 테이블을 참조하여 적절한 메서드를 찾습니다.
- 다중 상속 시 이름 충돌 및 다이아몬드 문제가 발생할 수 있습니다.
다이아몬드 문제 해결하기 (Dealing With Diamond Problem)
- 다중 상속의 경우, 상위 클래스에 공통 상위 클래스가 있을 때 다이아몬드 문제가 발생합니다.
- 예: A와 B가 TOP을 상속하고, Bottom이 A와 B를 상속하는 경우
- 이 경우 클래스 구성 방법에는 두 가지 방식이 있습니다:
- Replicated Inheritance: Bottom이 Top의 복제본을 가집니다.
- Sharing: Bottom이 Top의 한 가지 복사본만 가지고 공유해서 쓴다.
복제 다중 상속 (Replicated Multiple Inheritance)
Bottom이 Top의 복제본을 가지는 방식이다. 이 예제에서는 Top의 복제본이 두 개가 있다. (B에는 재정의된 f가 있다. 그리고 B 아래에 w가 한번 더 나타난다.)
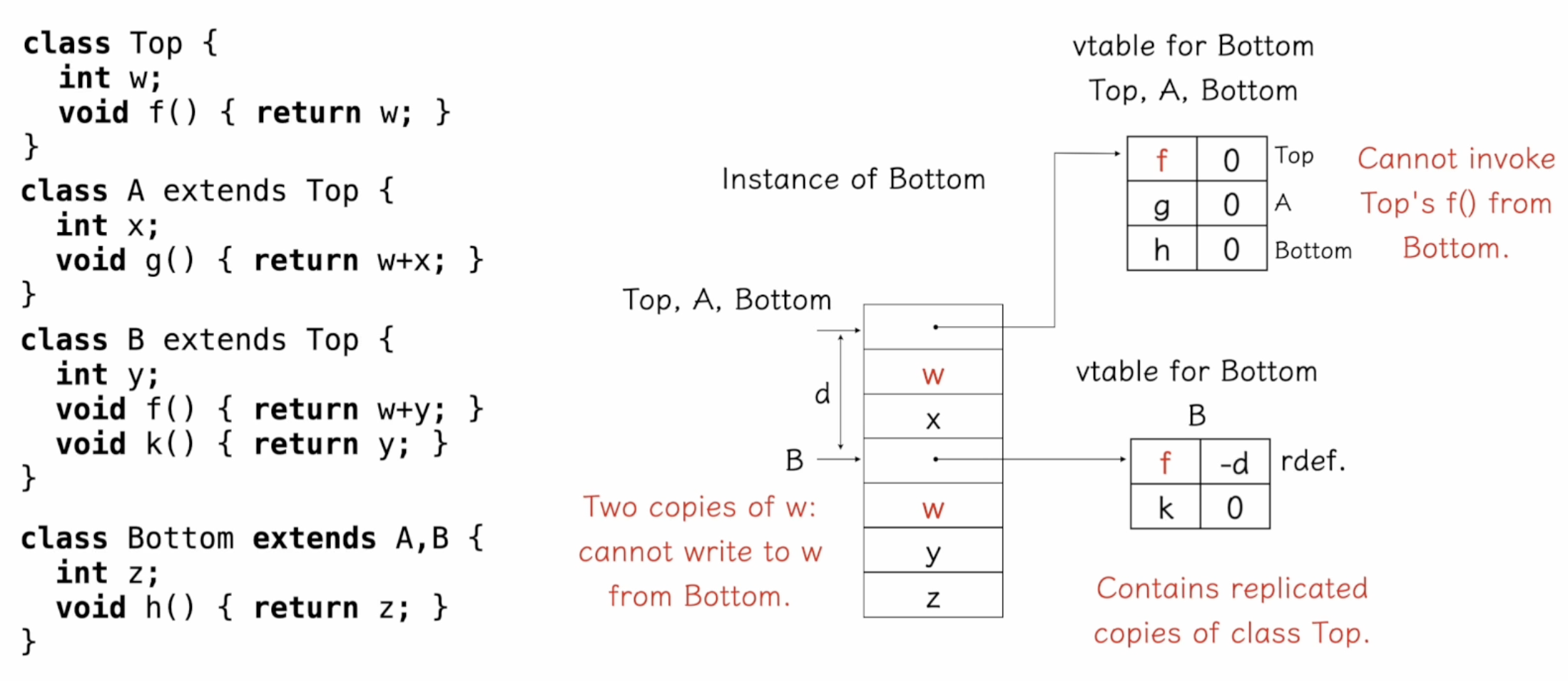
- Bottom 클래스는 Top의 복제본을 여러 개 가집니다.
- Top의 f() 메서드는 Bottom에서 호출할 수 없으며, 두 개의 w 필드가 존재하므로 Bottom에서 이를 수정할 수 없습니다.
- b.w = ?? -> 어떤 w 필드에 값을 적어야 할지 알 수 없다.
- b.f() -> Top의 f일까? B의 f일까?
- c++의 경우 다중 상속을 허용하는데, 이런 문제를 해결하기 위해 virtual keyword를 써서, 특정 함수가 무조건 자식 클래스에서 재정의되도록 한다. 그렇다면 B의 f가 호출되게 된다.
공유 다중 상속 (Multiple Inheritance w/ Sharing)
아까처럼 Top이 두 번 등장하는게 아니라, 한 번만 등장한다.
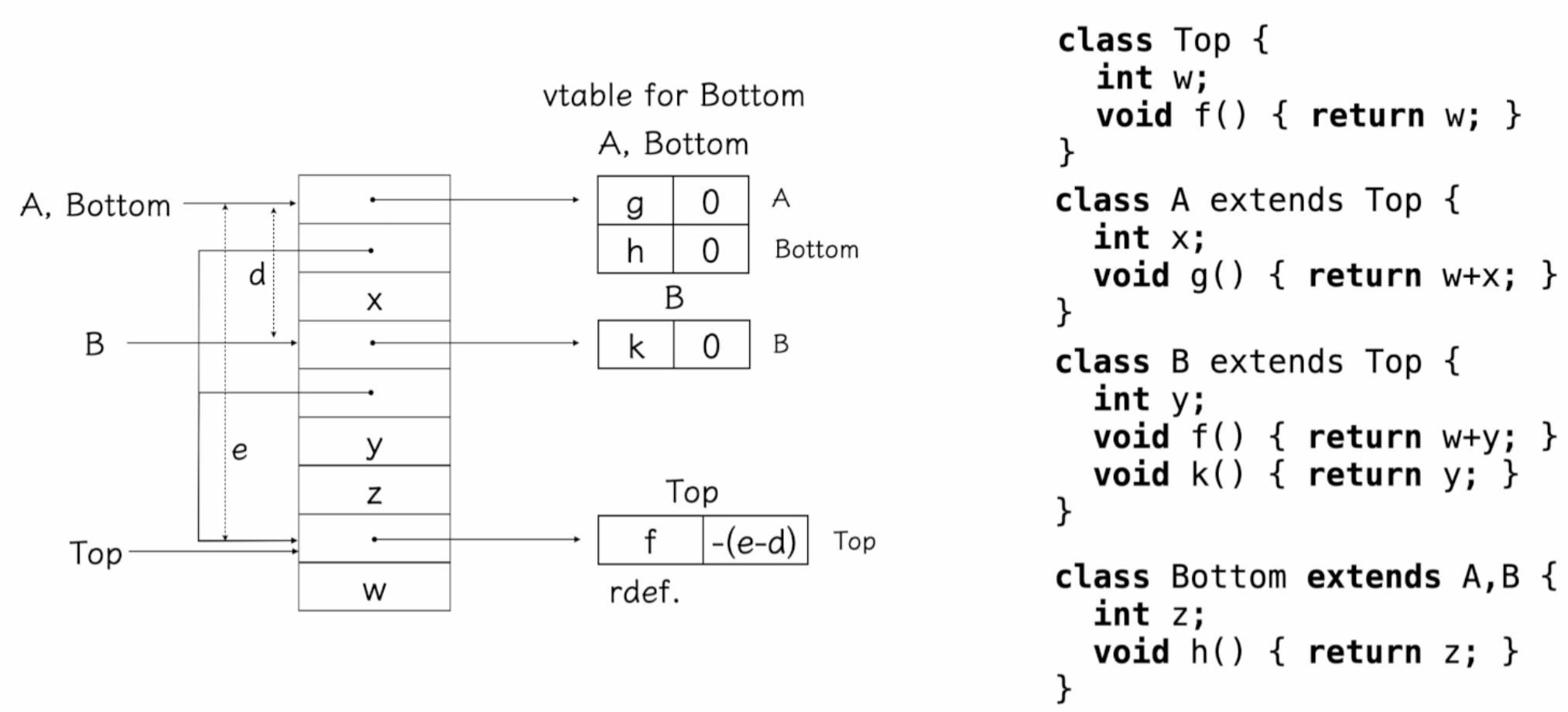
{Top, A, Bottom / Top, B}가 아니라, {A, Bottom / B / Top}이다.
A, Bottom 다음에 Top을 가리키는 포인터를 두고, B 다음에 Top을 가리키는 포인터를 둬서 공유해서 쓴다.
Bottom까지 모두 넣은 다음, 그 아래에다가 Top table과 변수를 놔둔다. Top table의 f함수는 redefine되어 필드의 값이 -(e-d)만큼 조정된다 => 여기로 왔으면 (-e-d)로 가서 호출하라는 말
⠀즉, vtable 엔트리 재정의로 인해 Top의 vtable 슬롯에 실제로는 B의 f 함수 포인터가 들어가 있으므로, Top의 vtable을 거쳐도 B의 f가 호출되는 것입니다.
이렇게 하면 어떤 장점이 있냐? Top table의 오프셋 필드 값이 0이면 top의 view가 되고, -k면 -k만큼 앞에 있는 곳의 view가 된다. 위 예시에서는 (-e-d)에는 B 테이블이 있으므로 B 테이블의 view라는 걸 알 수 있다. 포인터 보정이 이루어진다.
설명
- 공유 상속에서는 Top 클래스의 하나의 복사본만 사용됩니다.
- Bottom 클래스가 Top의 f() 메서드를 호출할 때, Bottom에서 Top의 데이터를 공유합니다.
- Top 클래스의 메서드 호출 시, 포인터 보정이 이루어져 올바른 가상 함수 테이블을 참조합니다.
공유 다중 상속에서의 f() 호출 (Calling f() of Bottom)
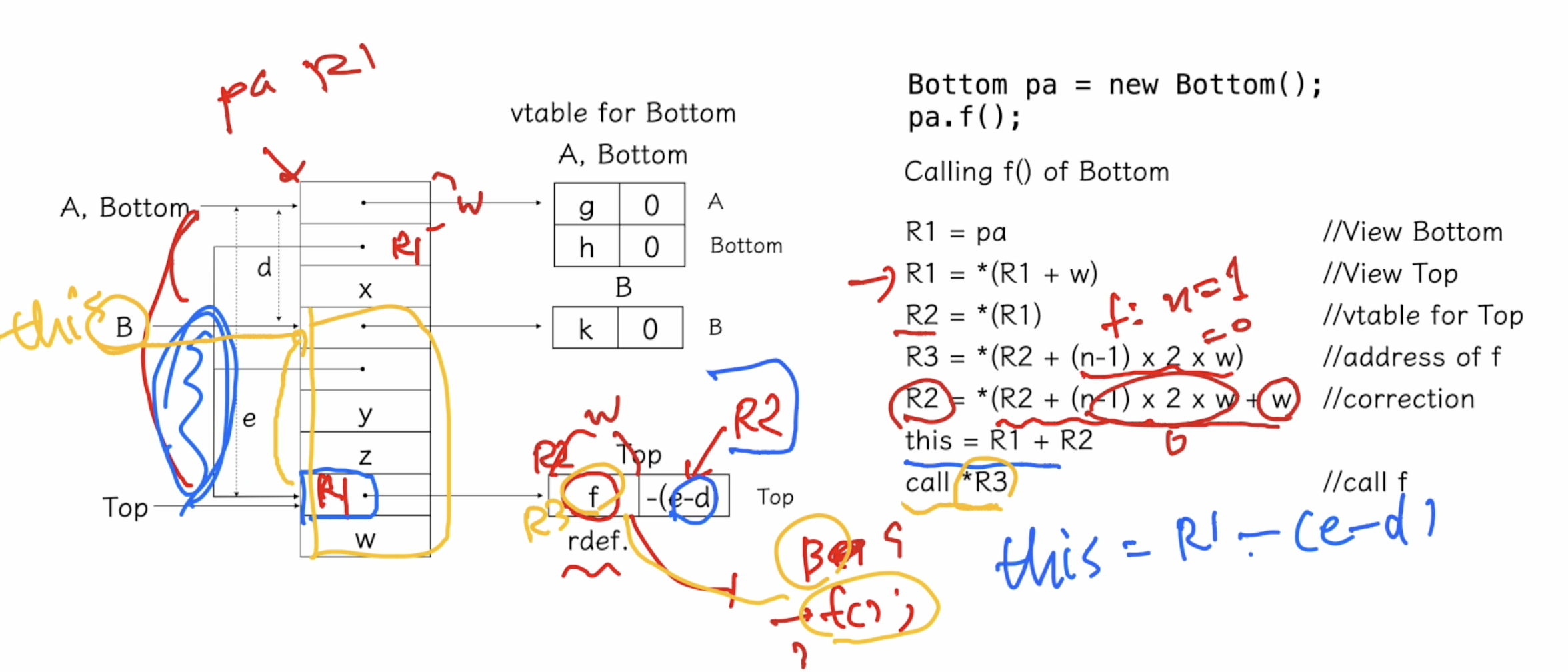
'Programming Language > Theory' 카테고리의 다른 글
| [PLT/프로그래밍언어론] 11. Functional Programming(2) (0) | 2024.12.22 |
|---|---|
| [PLT/프로그래밍언어론] 11. Functional Programming(1) (0) | 2024.12.22 |
| [PLT/프로그래밍언어론] 09. PL Paradigms, Scripting Language (0) | 2024.12.22 |
| [PLT/프로그래밍언어론] 08. 중간 정리 (0) | 2024.12.22 |
| [PLT/프로그래밍언어론] 07. Control Abstraction and Data Types (0) | 2024.12.21 |