File System Implementation
파일 시스템 구현 (File System Implementation)
- 사용자 관점에서의 파일 시스템 (File system of the user’s viewpoint)
- 파일 시스템을 사용자에게 어떻게 보여줄 것인가?
- 파일 시스템 인터페이스
- 파일, 디렉토리, 속성 및 작업
- 예: 트리 구조
- 저장 관리 관점에서의 파일 시스템 (File system of the storage management viewpoint)
- 논리적 파일 시스템을 저장 장치에 어떻게 매핑할 것인가?
- 파일 시스템 구현
- 레이아웃, 데이터 구조 및 알고리즘
- 저장 내부를 이해하는 것이 필요함
- 파일 시스템은 저장 장치를 블록의 시퀀스로 간주
- 디스크와 메모리 간의 데이터 전송은 블록 단위로 이루어짐.
- 각 블록에는 일반적으로 512바이트인 하나 이상의 섹터가 있음.

- 파일 시스템 구현 (File system implementation)
- 각 파일에 대해 속성(attribute)과 파일 데이터(file data)가 저장되어야 함.
- 속성 - 크기, 권한, 소유자, 시간 등
- 속성 및 파일 데이터를 저장할 공간을 어떻게 할당할 것인가?

- 파일 시스템 구현 (Unix file system)
- i-node
- 파일 데이터에 대한 속성 + 인덱스 (Attribute + indexes for file data)
- i-node 영역과 파일 데이터 영역은 분리됨
- i-node

- i-node 크기는 같지만, 파일 데이터의 크기는 다름
- i-number를 통해 i-node에 접근 가능
- 파일 데이터 저장 공간을 어떻게 할당할 것인가?
- 연속 (contiguous) / 링크 (linked) / 인덱스 (indexed) 할당
Contiguous Allocation
연속 할당 (Contiguous Allocation)
- 각 파일은 디스크의 연속된 블록 집합을 차지함
- 시작 위치와 길이만 필요함

- 파일에 순차/랜덤 접근이 쉬움
- 새 파일을 위한 공간 찾기가 어려움
Linked Allocation
연결 할당 (Linked Allocation)

- 각 파일은 디스크 블록의 연결 리스트(linked list)
- 예: MS-DOS 파일 시스템 (FAT 파일 시스템)
- 블록이 디스크 어디에나 흩어질 수 있음 → 공간 낭비 없음
- 순차 접근에만 효과적
- 포인터가 손실되거나 손상되면?
- MS-DOS의 FAT 파일 시스템
- 각 디스크 블록에 대한 항목이 하나 있음

참고)
FAT (File Allocation Table)
- 디스크의 각 블록에 대한 정보를 가지고 있습니다. 파일이 어떤 블록에 저장되어 있는지를 추적합니다.
작동 방식
- 파일 할당
- 파일이 디스크에 저장될 때, 파일의 데이터는 여러 데이터 블록에 저장됩니다.
- 예를 들어, 파일의 첫 번째 블록은 217번 블록에 저장되고, FAT의 217번 항목은 다음 블록 번호(618)를 가리킵니다.
- FAT 테이블의 역할
- FAT 테이블은 각 데이터 블록의 다음 블록 번호를 가리킵니다.
- 블록 217의 다음 블록은 618이며, 블록 618의 다음 블록은 339입니다.
- 블록 339은 파일의 끝을 나타내며(EOF), 더 이상 이어지는 블록이 없음을 표시합니다.
- 디렉토리 엔트리
- 디렉토리 파일에는 파일 이름과 함께 파일의 첫 번째 데이터 블록 번호가 저장됩니다.
- 이 예시에서는 파일 이름과 첫 번째 블록 번호(217)가 저장되어 있습니다.
Indexed Allocation
인덱스 할당 (Indexed Allocation)

- 모든 포인터를 인덱스 블록으로 가져옴
- 랜덤 접근 가능
- 연속된 블록을 찾을 필요 없음
- 파일당 하나의 인덱스 블록 필요
- 큰 파일을 위한 인덱스 블록의 크기가 여전히 작다면 문제가 발생한다
- 다단계 인덱스 (Multilevel index, 예: UNIX 파일 시스템)
- UNIX 파일 시스템의 i-node에 15개의 포인터 필드
- 직접 블록 (direct blocks)을 위한 12개의 포인터 필드
- 간접 블록 (indirect blocks)을 위한 3개의 포인터 필드
- 단일, 이중, 삼중
- UNIX 파일 시스템의 i-node에 15개의 포인터 필드

참고)
i-node 구조
i-node는 파일이나 디렉토리에 대한 정보를 가지고 있는 데이터 구조체로, 다음과 같은 필드를 포함합니다:
- mode: 파일의 타입 및 접근 권한
- owners: 파일의 소유자 정보
- timestamps: 파일의 생성, 수정, 접근 시간
- size block: 파일의 크기
- count: 파일을 참조하는 링크 수
- 포인터들:
- 12개의 직접 블록 포인터 (direct blocks): 파일의 데이터 블록을 직접 가리킵니다.
- 단일 간접 블록 (single indirect block): 이 포인터는 데이터 블록을 가리키는 또 다른 블록을 가리킵니다.
- 이중 간접 블록 (double indirect block): 데이터 블록을 가리키는 블록의 포인터를 다시 가리키는 블록을 가리킵니다.
- 삼중 간접 블록 (triple indirect block): 이중 간접 블록을 가리키는 블록을 가리킵니다.
데이터 블록 접근 방법
- 직접 블록 (Direct Blocks)
- i-node의 첫 12개 포인터는 직접 데이터 블록을 가리킵니다.
- 소형 파일의 경우 대부분의 데이터는 이 포인터들을 통해 직접 접근됩니다.
- 단일 간접 블록 (Single Indirect Block)
- i-node의 단일 간접 블록 포인터는 데이터 블록을 가리키는 포인터 블록을 가리킵니다.
- 이 블록을 통해 더 많은 데이터 블록을 참조할 수 있습니다.
- 이중 간접 블록 (Double Indirect Block)
- i-node의 이중 간접 블록 포인터는 단일 간접 블록들을 가리키는 블록을 가리킵니다.
- 파일이 더 클 경우, 이 구조를 통해 더욱 많은 데이터 블록을 참조할 수 있습니다.
- 삼중 간접 블록 (Triple Indirect Block)
- i-node의 삼중 간접 블록 포인터는 이중 간접 블록들을 가리키는 블록을 가리킵니다.
- 매우 큰 파일을 지원하기 위한 구조입니다.
결론) Indirect Block을 통해서 큰 파일에 접근할 수 있다.
Free Space Management
- 비트맵 (Bit map, bit vector라고도 함)
- 블록[i]가 할당되면 비트는 1; 그렇지 않으면 비트는 0.

- 연속된 여유 블록을 얻기 쉬움
- 비트맵은 추가 공간을 필요로 함
- 예: 블록 크기 = 2^12 바이트 (= 4KB)
- 디스크 크기 = 2^40 바이트 (= 1TB)
- n = 2^40/2^12 = 2^28 비트 (= 32MB)

- 연결 리스트 (Linked list)
- 공간 오버헤드 없음
- 연속된 여유 블록을 쉽게 얻을 수 없음
- 그룹화 (Grouping)
- 연결 리스트 접근법의 수정
- 처음 n-1의 여유 블록(free block)은 실제로 여유 상태
- 마지막 블록은 또 다른 n개의 여유 블록의 주소를 포함함

Directory Implementation
디렉토리 구현 (Directory Implementation)
- 선형 리스트 (Linear list)
- (파일 이름, 파일에 대한 포인터)
- 구현이 간단함
- 파일 검색에 시간이 많이 소요됨
- B-트리를 사용할 수 있음
- 해시 테이블 (Hash Table)
- 해시 데이터 구조를 가진 선형 리스트
- 해시 함수는 "파일 이름"을 "파일의 선형 리스트에 대한 포인터"로 변환
- 디렉토리 검색 시간을 줄임
- 충돌을 해결해야 함
Performance and Recovery
성능 및 복구
- 효율성 (Efficiency)
- 파일의 데이터 블록을 해당 파일의 i-node 블록 근처에 유지하여 검색 시간을 줄임.
- i-node의 "마지막 접근 시간" 정보는 블록 읽기와 쓰기를 필요로 함.
- 데이터 접근에 사용되는 포인터의 크기? 16bit 또는 32bit.
- 성능 (Performance)
- 버퍼 캐시 (Buffer cache)
- 자주 사용되는 블록을 위한 메인 메모리의 별도 섹션
- 읽기 선행 (read-ahead)
- 순차 접근을 최적화하기 위한 기술
- 버퍼 캐시 (Buffer cache)
- 버퍼 캐시 (Buffer cache)
- 파일이 접근될 때마다 파일 데이터는 디스크에서 가져와야 함.
- 그러나 디스크 접근은 큰 I/O 오버헤드를 발생시킴.
- 파일 접근 패턴에서 한 번 접근된 데이터는 곧 다시 사용될 것임 (시간적 지역성, temporal locality).
- 버퍼 캐시는 곧 다시 사용될 블록을 유지하여 디스크 접근을 줄임.
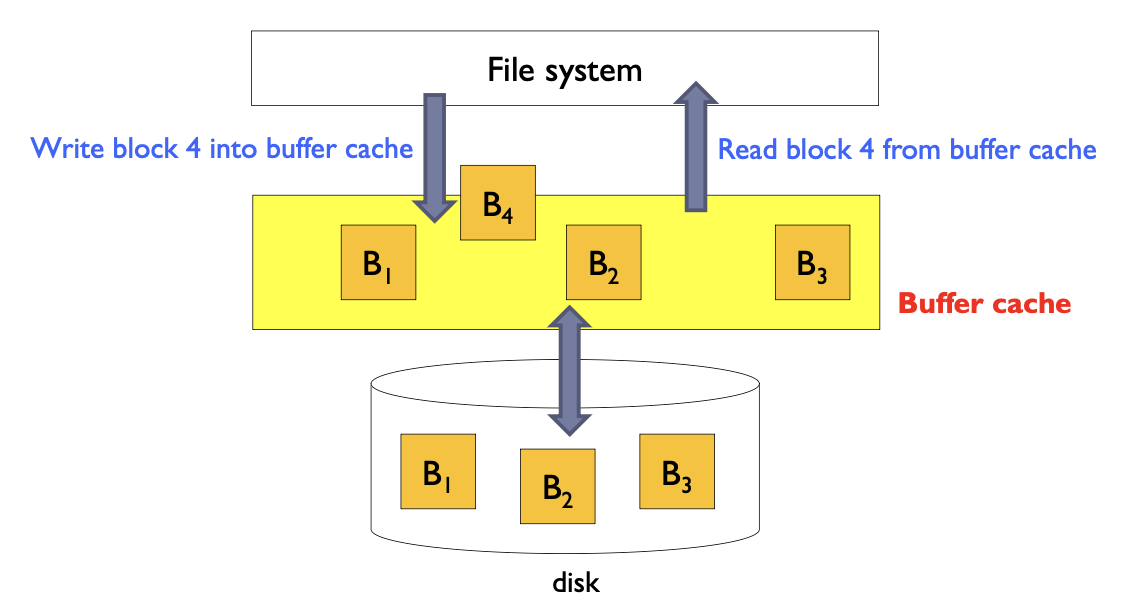
- 불일치가 발생할 수 있음 (Inconsistency can occur)
- 파일 시스템의 일부가 속도 향상을 위해 메모리에 유지됨.
- 시스템이 충돌하면? 모든 데이터를 디스크에 저장할 수 없음.
- 디렉토리 또는 메타데이터(i-node)가 손실되면?
- 일관성을 위한 솔루션 (Solutions for consistency)
- 일관성 검사기(Consistency checker)
- e.g. UNIX의 fsck
- 디스크의 데이터 블록과 디렉토리 구조의 데이터를 비교하고 불일치를 수정하려고 시도.
- 중요한 메타데이터를 위한 동기식 쓰기 (Synchronous write)
- 저널링 (Journaling)
- 일관성 검사기(Consistency checker)
- 시스템 프로그램을 사용하여 데이터 백업 (Use system programs to back up data)
- 디스크에서 다른 저장 장치로
- 백업 데이터를 복원하여 손실된 파일 또는 디스크 복구
'Computer Science > OS' 카테고리의 다른 글
| [운영체제] 13. File System Interface (0) | 2024.06.19 |
|---|---|
| [운영체제] 12. I/O Systems (0) | 2024.06.19 |
| [운영체제] 11. Mass-Storage Structure (0) | 2024.06.19 |
| [운영체제] 10. Virtual Memory (0) | 2024.06.19 |
| [운영체제] 09. Main Memory (0) | 2024.06.19 |